
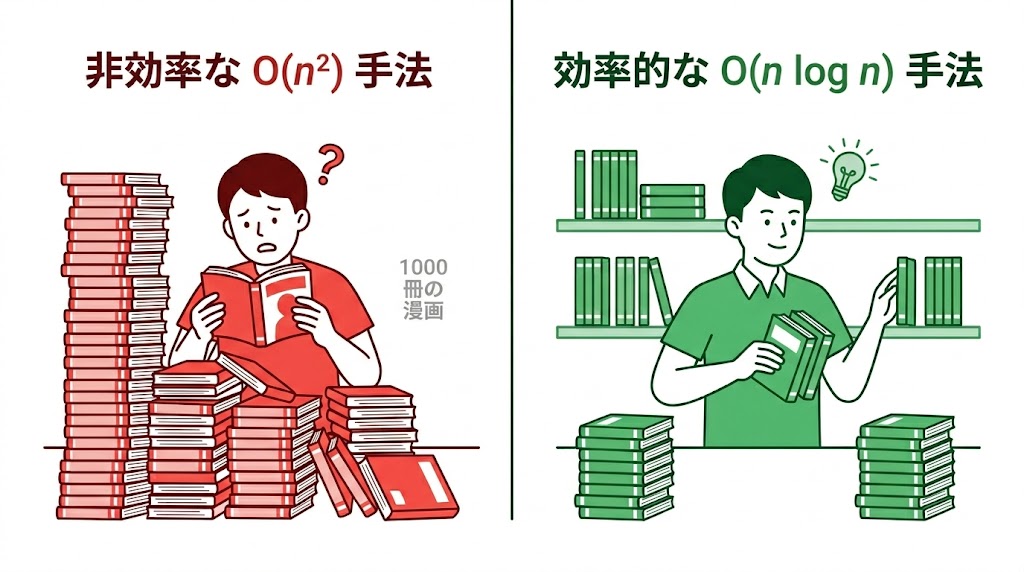
もしあなたが、バラバラになった1000巻の漫画を片付けようとして、「まず1巻を探して左端に置き、次に2巻を探してその右に置く」という手順を迷わず選んだとしたら。
コンピュータ科学の世界では、こう一蹴される。「それダッサいっすね。オーダーN2乗のアルゴリズムじゃん」と。
情シス22年の現場で、システムのパフォーマンス問題を何十件と診断してきた。「なぜデータが増えると急に遅くなるのか?」という質問の答えは、ほぼ全ていま説明する「オーダー(計算量)」の概念に行き着く。仕組みを理解しているエンジニアとそうでないエンジニアでは、設計の段階で差が開く。
この記事でわかること:
- 「1冊ずつ順番に探す」がなぜデータ量が増えると地獄になるのか
- コンピュータ科学の最重要単語「オーダー(O記法)」の正体
- N²とN log Nで実際何倍の差が出るのか(100万件なら5万倍)
- logを活用したアルゴリズムが直感に反して最速になる理由
1. あなたの漫画並び替え方法は「ダサい」?選択ソートという罠
📌 要点:バラバラの漫画を1冊ずつ確定させていく「選択ソート」はデータ数Nに対してN²回の計算が必要。データが増えるほど手間が指数関数的に膨らむ「ダサいアルゴリズム」の代表例だ。
バラバラの漫画を並べる際、多くの人が直感的に選ぶ「1冊ずつ場所を確定させていく方法」は、コンピュータ科学では「選択ソート(セレクションソート)」と呼ばれる。
手順:
- バラバラの山から「1巻」を探し出し、本棚の左端に置く
- 残りの山から「2巻」を探し出し、1巻の隣に置く
- これを最終巻まで繰り返す
誰でもできる立派な手順に見えるが、アルゴリズムの評価軸はたった一つ、「早く終わったほうが偉い」というシビアな世界だ。
計算回数の現実:
1000巻の漫画を並べるとき、最初の1巻を探すには最悪1000冊全てをチェック。次に2巻を探すときは999冊、3巻なら998冊……。平均すると毎回「残りの半分」を確認している。
「平均500回のチェック」を1000回繰り返すと、合計の計算回数は約50万回。データの個数をNとすると、およそN²に比例した手間がかかる。これが「N²のアルゴリズム」の正体であり、エンジニアが「ダサい」と呼ぶ理由だ。
2. コンピュータ科学の最重要単語「オーダー」の恐怖
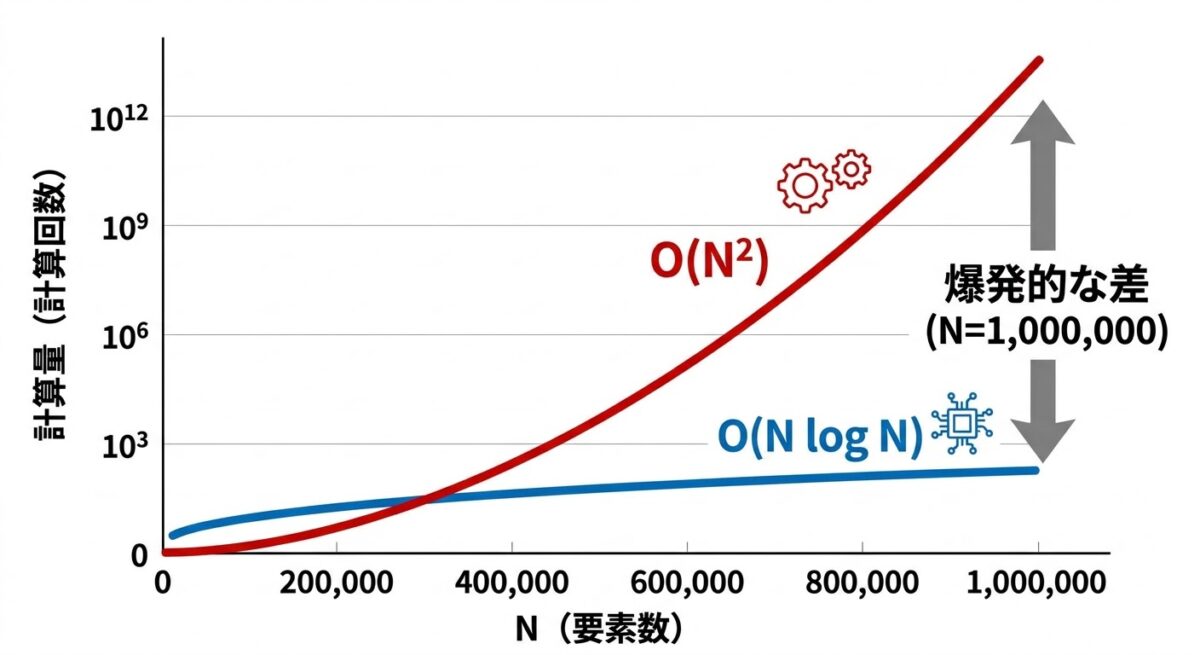
📌 要点:オーダー(O記法)とは「データが増えたとき計算の手間がどれくらい増えるか」という勢いを示す指標。係数や端数を切り捨て「一番影響が大きい部分」だけを見る。N=100万のときN²は1兆になる。
「データの数が増えたときに、計算の手間がどれくらい増えるか」という増加の勢いを示す指標を、「オーダー(O記法)」と呼ぶ。
選択ソートのオーダーは O(N²) と表現する。コンピュータ科学者は細かい係数や端数をバッサリ切り捨て「一番影響が大きい部分」だけを見る。なぜ係数を無視するか。Nが大きくなったとき、N²の増加率が他のすべてを圧倒するからだ。
オーダー別の計算回数(N=100万の場合):
| オーダー | 計算回数 |
|---|---|
| O(log N) | 約20回 |
| O(N) | 100万回 |
| O(N²) | 1兆回 |
正直、データが数件しかないならダサいと言われた選択ソートの方が速いこともある。仕組みが単純な分、準備運動がいらないからだ。しかし、プロの現場で扱うデータ量は常に増え続ける。
医療機関のシステムで患者データを処理する際、「なぜ数千件のときは速かったのに数十万件になると遅くなるのか」というトラブルを経験した。原因を調べると、内部の並び替え処理がO(N²)で実装されていた。データが10倍になると計算量は100倍になる。これが現実の問題だ。
3. 1兆回が2000万回に?logの劇的効率
📌 要点:並び替えの理論的最善はO(N log N)。logはNが大きくなっても驚くほど増えない特性を持つ。N=100万のとき、O(N²)の1兆回に対してO(N log N)は約2000万回——その差は5万倍。
並び替え(ソート)の世界において、現在最善とされているオーダーは O(N log N) だ。ここで多くの人が高校数学でアレルギーを起こした「log(ログ)」が、最強の武器として登場する。
logの本質を一言で言えば:「半分に分け続けると最強になる魔法の杖」だ。
logの最大の特徴は、Nが大きくなっても数値が驚くほど増えないことだ。
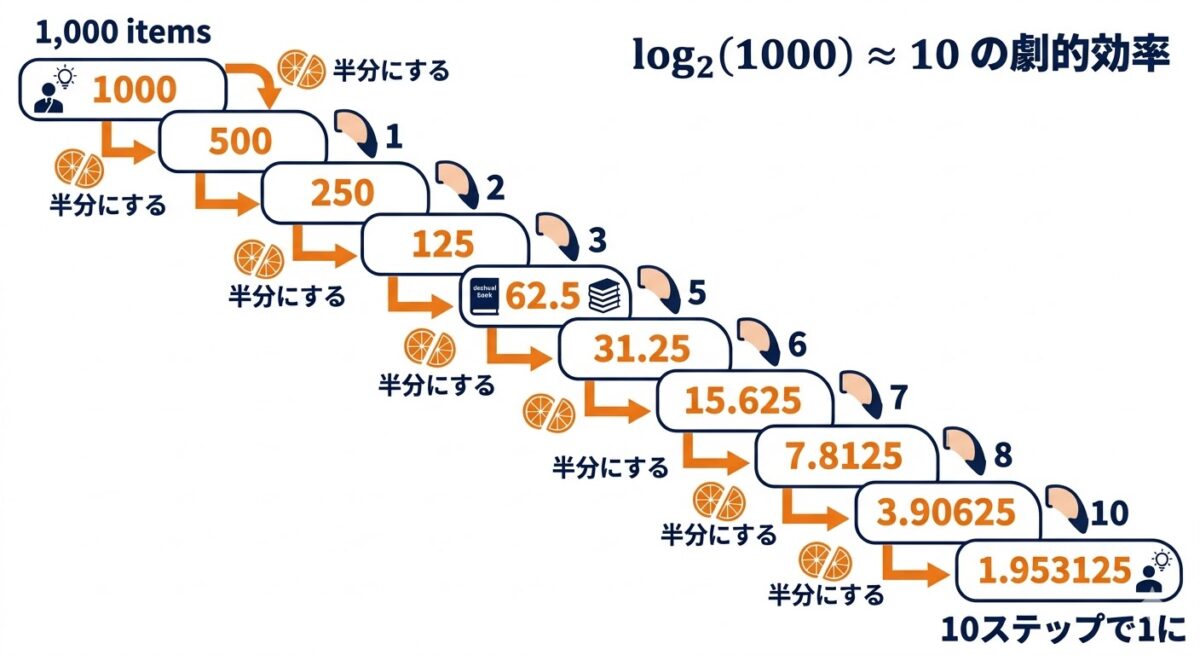
1,000 を半分にし続けると?
1000 → 500 → 250 → 125 → 63 → 32 → 16 → 8 → 4 → 2 → 1
わずか10ステップで「1」に到達する。これがlog₂(1000) ≈ 10 の意味だ。
データが100万個あるとき:
| アルゴリズム | 計算回数 |
|---|---|
| O(N²) | 100万 × 100万 = 1兆回 |
| O(N log N) | 100万 × 20 = 2,000万回 |
その差は実に5万倍。O(N²)ならコンピュータが一生かかっても終わらないような作業が、O(N log N)ならお昼休みが終わる前に完了する。
この圧倒的な差を生み出すのが「クイックソート」や「マージソート」といった、全体を効率よく分割して処理するアルゴリズムだ。
4. 巧妙なトリック。良いアルゴリズムは「心地よい驚き」を持つ
📌 要点:良いアルゴリズムは単に効率的なだけでなく「巧妙なトリックと心地よい驚き」を感じさせる。直感を疑い、手順を変えるだけで解法(アルゴリズム)のオーダーは劇的に改善できる。
「良いアルゴリズムというものは、巧妙なトリック、心地よい驚きを感じることができるものである」
コンピュータ科学の醍醐味は、こうした「賢い解法」に出会ったときの感動にある。
日常業務に置き換えると:
大量の書類から特定の1枚を探すとき、端からめくっていくのはO(N)だ。しかし、もし書類が五十音順に並んでいるなら、真ん中をめくって範囲を絞り込む「二分探索」を使えばO(log N)まで落ちる。100万枚の書類があっても、わずか20回めくるだけで目的の1枚に辿り着ける計算だ。
闇雲に努力するのではなく、まずその問題に対する「解法(アルゴリズム)」を疑ってみる。その視点を持つだけで、仕事の生産性は文字通り「次元が変わる」ほど向上する。
FAQ:よくある質問
Q. オーダーの概念はプログラミング以外でも使えますか?
使用可能です。
例えばエクセルで1万行のデータを手動で処理するとき、「1行ずつ確認する(O(N))」か「ソートして一括処理する(O(N log N))」かの選択は、まさにオーダーの選択だ。処理の手順を変えるだけで作業時間が劇的に変わる場面は日常業務にも多い。
Q. O(N²)が絶対ダメというわけではないですか?
その通りで、データが少ない場合はO(N²)の方が速いこともある。
オーバーヘッドが少ない単純な処理は、データが数十件程度なら十分実用的だ。問題は「データが増えたとき」に手間が爆発するという点で、スケールする設計が必要な場面では選んではいけない。
Q. O(1)とはどういう意味ですか?
データ数に関係なく一定の計算回数で済むオーダーだ。
ハッシュテーブルの検索がこれに当たる。「どのデータが何番の箱にあるか最初から決まっている」ため、探す手間がデータ数によらず一定になる。これが最強のオーダーだが、事前の設計コストが高い。
Q. log₂とlog₁₀は違いますか?
違います。数学的な結論から言うと、log₁₀x は log₂x の約0.3倍の大きさです。
log₂は「2で何回割ったら1になるか」、log₁₀は「10で何回割ったら1になるか」という意味だ。コンピュータは2進法で動くため、アルゴリズムの計算量ではlog₂を使うことが多い。ただしオーダー記法では底は定数倍の差しかないため、どちらを使っても「O(log N)」と書く。
Q. クイックソートが最速なら、なぜ他のソートアルゴリズムが存在するのですか?
最悪ケースでO(N²)になるという弱点があるからです。
既にほぼ整列されたデータや特定のパターンのデータに対しては、マージソートやヒープソートの方が安定して速い。「どんなデータが来ても安定して速い」かどうかが実務での選択基準になる。
まとめ
アルゴリズムの真の評価はPCのスペックに依存しない「計算回数の増加率」で決まる。
- 1冊ずつ順番に確定させる選択ソートはO(N²)で、データが増えると指数関数的に遅くなる
- オーダー(O記法)はビジネスにおける「スケールアップへの耐性」を示す指標だ
- logを活用したO(N log N)のアルゴリズムは、N=100万でO(N²)の1兆回に対して2000万回——5万倍の差がある
- 闇雲に努力するより「解法のオーダーを落とす」視点が、仕事の生産性を劇的に変える
次にあなたが膨大なエクセルデータに立ち向かうとき、「この作業のオーダーを落とすには?」と自分に問いかけてほしい。その瞬間、単なる作業者から世界を効率化する思考者への第一歩を踏み出している。
関連記事:アルゴリズムの本質は「紙とペン」に宿る
関連記事:二分探索木(BST)とは?計算量O(log n)の仕組みを図解でわかりやすく解説

