
「データが多すぎて、探すのに時間がかかる……」
そんな悩みを解決するのがデータ構造の優等生、二分探索木(BST:Binary Search Tree)だ。
結論から言えば、二分探索木は「速く探すために、データの居場所をあらかじめ振り分ける構造」だ。
情シスとしてデータベースの設計・運用に長年関わってきた。数億件のレコードから特定データを探す場面で、「この設計では絶対に遅くなる」とわかる瞬間がある。二分探索木の概念を知っているかどうかが、その判断の分岐点になる。
この記事でわかること:
- 二分探索木が「左は小さく、右は大きい」だけで爆速になる理由
- 配列との本質的な違い(検索と追加のトレードオフ)
- 偏りによる最悪ケースとバランス木への進化
- 実務でどこに使われているか
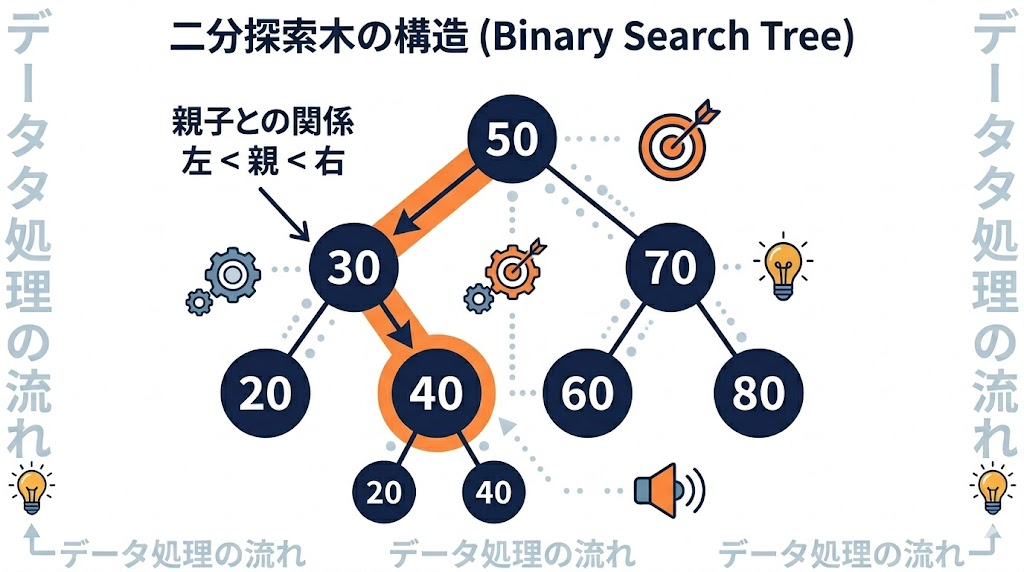
1. 二分探索木とは?「左は小さく、右は大きい」の魔法
📌 要点:二分探索木の絶対ルールは「左の子は親より小さく、右の子は親より大きい」のみ。このルールにより探索のたびに候補が半分に削ぎ落とされ、O(log n)の速度が実現する。
二分探索木は、データが親子関係でつながる「木構造」の代表格だ。最大の特徴は、たった一つの絶対的なルールでデータが整理されていること。
二分探索木の絶対ルール:
- 左の子:親より「小さい」データ
- 右の子:親より「大きい」データ
このルールがあるおかげで、例えば「10」を探すとき、親が「15」なら迷わず左の枝へ進めばいい。探すたびに選択肢が半分に削ぎ落とされる、これが爆速検索の秘密だ。
100万件のデータがあっても、半分ずつ削ぎ落としていくと約20回で1件に到達できる。この「20回」という驚異的な速さが O(log₂ n) だ。
2. なぜ「ニョキニョキ」枝分かれするのか?
📌 要点:新しいデータを追加するとき、二分探索木はルートから比較を繰り返し「あるべき場所」を自動で探して伸びる。小さいものは左、大きいものは右に振り分けながら自然にバランスよく成長する。
新しいデータを追加するとき、二分探索木は自動的に「あるべき場所」を探して伸びていく。
「15」を追加するシミュレーション(ルートが「10」の場合):
- ルート(10)と比較:15は大きいから「右」へ
- 次の子(20)と比較:15は小さいから「左」へ
- 空き地に到着:ここに「15」が着座
データが入るたびに、小さいものは左、大きいものは右……と繰り返すことで、自然にバランスよく枝が広がる。これが「ニョキニョキ」と成長する正体だ。
3. 配列 vs 二分探索木:どっちが優秀?
📌 要点:配列はソート済みなら検索はO(log n)だが追加がO(n)(全体をずらす必要あり)。二分探索木は検索も追加も平均O(log n)で「攻守最強」のバランスを持つ。
「最初から並べた配列でいいのでは?」という疑問は当然だ。しかしデータの「追加」が発生すると差が出る。
| 構造 | 検索スピード | データの追加 | 総合評価 |
|---|---|---|---|
| 配列(未ソート) | 遅い(O(n)) | 速い(O(1)) | 探すのが苦行 |
| ソート済み配列 | 速い(O(log n)) | 非常に遅い(O(n)) | 挿入で全体がズレる |
| 二分探索木 | 速い(平均O(log n)) | 速い(平均O(log n)) | 攻守最強のバランス |
ソート済み配列で新しいデータを「正しい位置」に追加しようとすると、そこより後ろの要素を全部1つずらす必要がある。10万件のデータの先頭に挿入すれば、10万回の移動が発生する。これがO(n)の「現実の絶望的な遅さ」だ。
4. 弱点:偏ると「ただの棒」になってしまう
📌 要点:「1, 2, 3, 4, 5」と順番通りに追加すると右側にだけ伸び、実質O(n)の線形探索と同じになる。これを防ぐため実際のシステムでは「自己平衡木(赤黒木・AVL木)」が使われる。
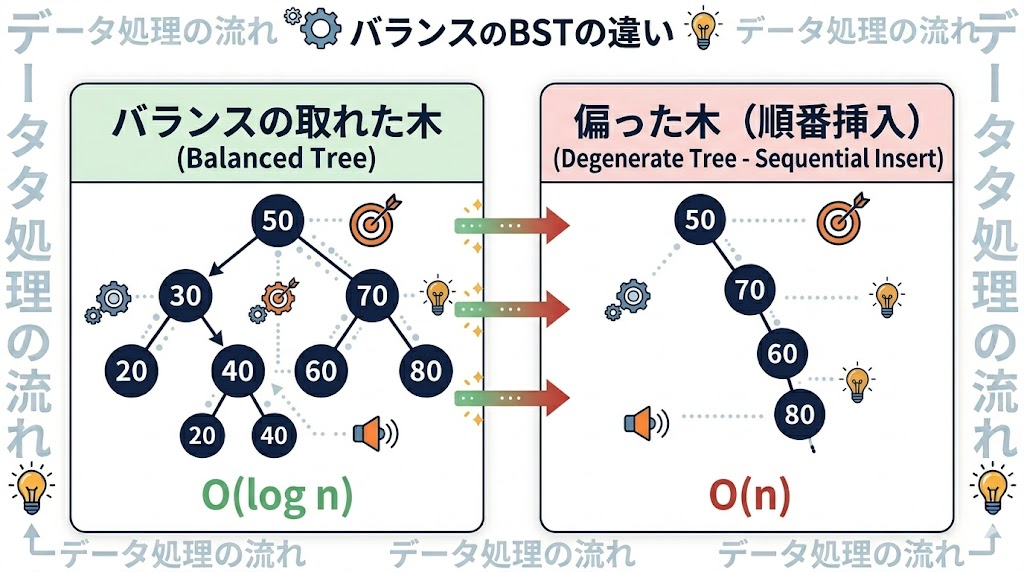
二分探索木には唯一にして最大の弱点がある。
「1, 2, 3, 4, 5」と順番通りにデータを追加してしまうとどうなるか。右側にだけニョキニョキ伸びて、実質的に「ただの長い列(配列)」になってしまう。
これでは検索スピードは最悪のO(n)。100万件のデータで最大100万回の比較が必要になる。
これを防ぐために、木が傾いたら自動で形を整える「自己平衡木(赤黒木・AVL木など)」という進化形が実際のシステムでは使われている。JavaのTreeMapやC++のmapは内部的に赤黒木を採用している。
5. 実際どこで使われているか?
📌 要点:DBのインデックス・スマホの予測変換・ファイルシステムの検索など、現代社会のインフラを支える多くの場所で二分探索木の派生構造が動いている。
「そんな木構造、いつ使うの?」と思うかもしれないが、現代社会のインフラを支えている。
- データベースのインデックス:数億件のレコードから瞬時に特定のIDを探す
- スマホの予測変換:文字を打つたびに候補が出る仕組みの裏側
- ファイルシステム:PC内の膨大なファイルから特定の名前を検索する
MySQLのInnoDBストレージエンジンはB+Treeという二分探索木の派生構造をインデックスに採用している。「クエリが遅い」というトラブルの診断でEXPLAINを使うとき、インデックスが機能しているかどうかを確認するのはこの知識があってこそだ。
FAQ:よくある質問
Q. 二分探索木と「二分探索」は同じですか?
A. 違う。「二分探索」は並んだデータに対するやり方(アルゴリズム)。「二分探索木」は、そのやり方を効率的に行うための入れ物(データ構造)だ。アルゴリズムとデータ構造は車の両輪のような関係で、セットで理解するのが重要だ。
Q. なぜ計算量が「log」になるのですか?
A. 1回探すたびに、残りの範囲が「半分」になるからだ。100万件のデータがあっても、2で割り続けるとわずか20回で1になる。この「20回」が log₂(1,000,000) ≒ 20 だ。
Q. 自己平衡木(赤黒木・AVL木)はいつ選びますか?
A. 挿入順序が予測できないデータを扱う場合はほぼ常に自己平衡木を選ぶ。実際、JavaやC++の標準ライブラリのSortedMap/Setは内部的に赤黒木を採用している。純粋な二分探索木を自作で使う場面は学習目的か、挿入順序が制御できる特殊なケースに限られる。
Q. ハッシュテーブルと二分探索木はどう使い分けますか?
A. 「完全一致検索のみ」ならハッシュテーブルが速い(O(1))。「範囲検索・順序を保持した検索」が必要なら二分探索木を選ぶ。「20〜30の範囲にある要素を全部取り出せ」という操作は二分探索木でO(log n)でできるが、ハッシュテーブルでは苦手だ。
Q. Pythonでは二分探索木をどう使いますか?
A. Pythonの標準ライブラリには純粋な二分探索木はない。sortedcontainersライブラリのSortedList・SortedDictが実質的に同等の機能を提供している。競技プログラミングではよく使われるので、インストールしておくと便利だ。
まとめ
二分探索木は、プログラミング学習において「計算量の感覚」と「構造設計の美しさ」を学ぶ最高の教材だ。
- 左は小、右は大:これだけで検索が O(log n) になる
- 平均O(log n):データが増えても重くなりにくい。100万件でも約20回で探せる
- 偏りに注意:バランスが崩れるとO(n)まで劣化。実用では自己平衡木を使う
- 実務での存在感:DBインデックス・予測変換・ファイルシステムに組み込まれている
「ニョキニョキ」の仕組みを理解すれば、アルゴリズムの世界が一気にクリアに見えてくる。なぜDBのクエリが速いのか、なぜインデックスを貼ると速くなるのか。その答えがここにある。
関連記事:スタックとキューの使い分け完全ガイド
関連記事:アルゴリズムの本質は「紙とペン」に宿る
“`

