ブラウザに並ぶ「縺ゅ」「」「〓」。
文字化けは故障ではない。「同じバイト列を、別の辞書で読んでしまった結果」だ。
情シス担当者として現場で、文字化けの問い合わせを何十件と対応してきた。「メールの本文が全部記号になった」「CSVを開いたら日本語が消えた」「Webフォームから送信したデータが化けて届く」……パターンは様々だが、原因は毎回同じ構造だ。仕組みを知っているだけで、原因の特定時間が30分から3分に縮まる。
この記事でわかること:
- 文字コードの「2層構造」とUTF-8とShift_JISの本質的な違い
- 「縺ゅ」が生まれる仕組みとなぜ「0.2999…」でなく特定の文字になるのか
- 黒いダイヤ「」とBOMの正体
- MySQLのutf8がなぜ罠なのか
- 実務で絶対守るべき3つの鉄則
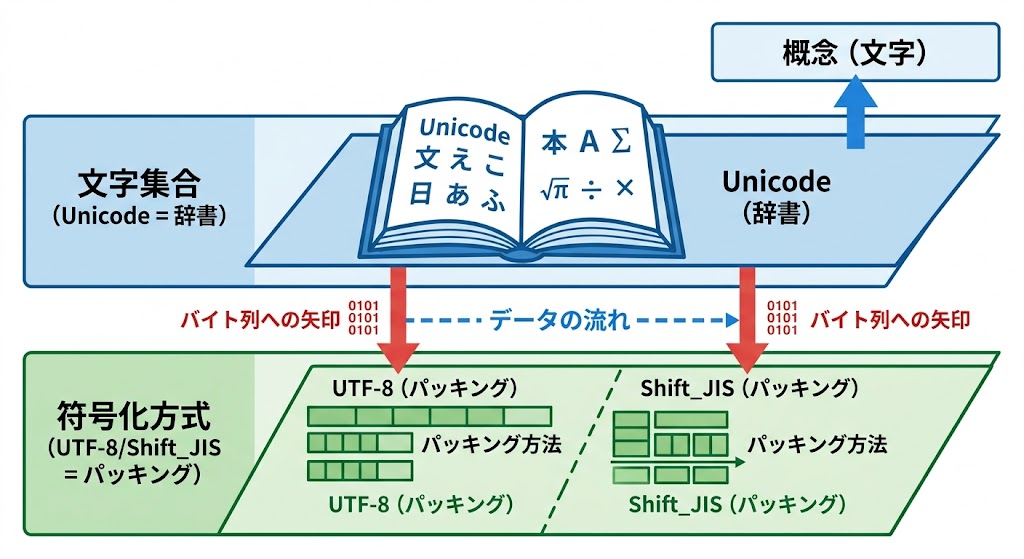
1. 文字コードの本質:文字集合と符号化は別物
📌 要点:文字コードは「どの文字にどの番号を割り当てるか(文字集合)」と「その番号をどうバイト列にするか(符号化方式)」の2層構造になっている。この2つを混同すると理解が止まる。
文字コードは2層構造で成立している。
- 文字集合(Character Set):どの文字にどの番号を割り当てるか(例:Unicode)
- 符号化方式(Encoding):その番号をどう「0と1」のバイト列にするか(例:UTF-8、Shift_JIS)
比喩で理解:
Unicodeは「巨大な漢字辞典(中身)」そのもの。UTF-8は「その辞書をデジタルで運ぶためのパッキング方法」だ。
同じ「Unicodeの辞典」を使いながら、UTF-8とUTF-16ではパッキング方法が異なる。一方、Shift_JISは全く別の辞典体系だ。ここを混同すると文字化けの原因が見えなくなる。
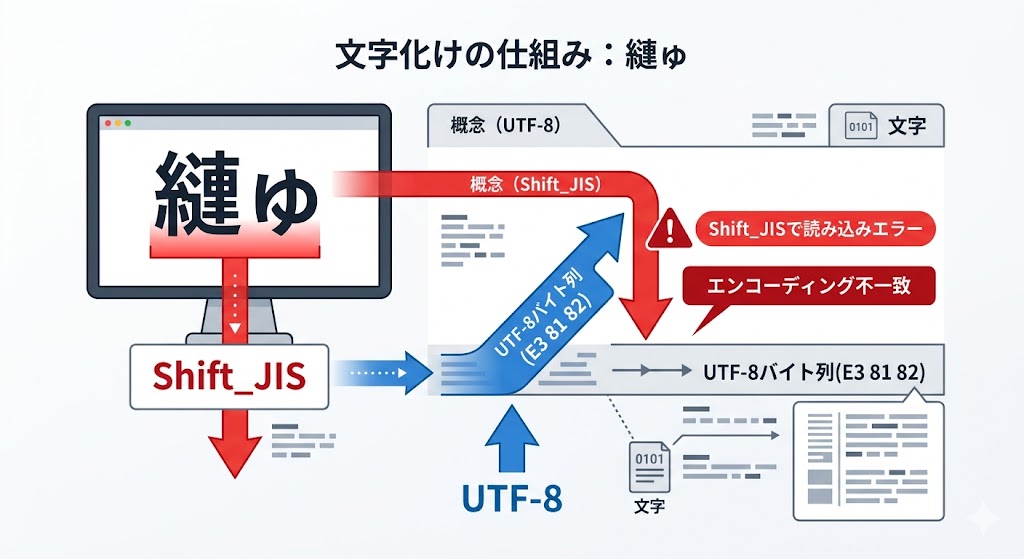
2. 実例:「あ」はどう保存されているか?
📌 要点:同じ「あ」でもUTF-8では「E3 81 82」(3バイト)、Shift_JISでは「82 A0」(2バイト)と全く異なるバイト列になる。UTF-8で保存したファイルをShift_JISで開くと区切り位置がズレて「縺ゅ」になる。
同じ「あ」でも、符号化方式によってバイト列は劇的に変わる。
UTF-8 の「あ」:
E3 81 82 (3バイト使用)Shift_JIS の「あ」:
82 A0 (2バイト使用)何が起きるのか:
UTF-8で保存された E3 81 82 を、無理やりShift_JISとして読もうとすると「縺ゅ」という別の文字になる。
理由はシンプルだ。
- UTF-8は「3バイトで1文字」と解釈する
- Shift_JISは「2バイト単位」で区切る
「区切り位置がズレる」。これが文字化けの正体だ。
医療機関での電子カルテ移行作業で、旧システムのShift_JIS形式で保存されたデータを新システムにUTF-8で取り込んだとき、患者名が全部文字化けした。「バックアップに問題があった?」と焦ったが、原因は単純なエンコードの不一致だった。変換処理を一本はさむだけで全員の名前が正しく表示された。仕組みを知っていれば5分で解決できる問題だ。
3. よく見る「」とBOMの罠
📌 要点:黒いダイヤ「」はU+FFFD(解釈不能なバイトが来たというエラー表示)。BOMはWindows環境で付与される先頭の見えない3バイトで、PHPのヘッダー出力エラーやJSONパース失敗の原因になる。
黒いダイヤ「」の正体:
これは U+FFFD(REPLACEMENT CHARACTER) だ。「解釈不能なバイト列が来た」というエラー表示で、コンピュータが「読めなかった」と正直に白旗を上げている状態だ。「壊れている」のではなく、エンコードが合っていないだけなので、正しいエンコードで読み直せば解決する。
見えない地雷「BOM(Byte Order Mark)」:
Windows環境のメモ帳やエディタでUTF-8保存すると、先頭に目に見えない3バイト(EF BB BF)が付与されることがある。
これが引き起こすトラブル:
- PHPでHTMLヘッダーより前に謎の空白が出る
- JSONのパースが失敗する(先頭の
{の前にBOMが混入するため) - APIレスポンスが壊れる
目に見えない3バイトが、システムを密かに破壊する。テキストエディタで保存するときは「UTF-8(BOMなし)」を選ぶのが鉄則だ。
4. 2026年の実務:サロゲートペアとMySQLの罠
📌 要点:絵文字は4バイト(UTF-8)でMySQLの古い「utf8」設定では3バイトまでしか扱えないため絵文字が入ると壊れる。必ず「utf8mb4」を使うこと。
「1文字=1バイト」の時代はとっくに終わっている。
絵文字「😀」のサイズ感:
| 符号化方式 | バイト列 | バイト数 |
|---|---|---|
| UTF-8 | F0 9F 98 80 | 4バイト |
| UTF-16 | D83D DE00 | サロゲートペア(2つの16bit単位) |
MySQLの「utf8」は罠:
MySQLの古い utf8 設定は3バイトまでしか扱えない。絵文字は4バイトなので、utf8 のまま絵文字を含む文字列をINSERTすると、その場でデータが壊れる(切り詰められる)か、エラーになる。
絵文字を扱うなら必ず utf8mb4 を使うこと。
ALTER TABLE your_table CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;これを知らないまま本番環境でリリースして、ユーザーが絵文字を含むプロフィールを保存した瞬間にデータが壊れるというトラブルは、今でも定期的に発生している。
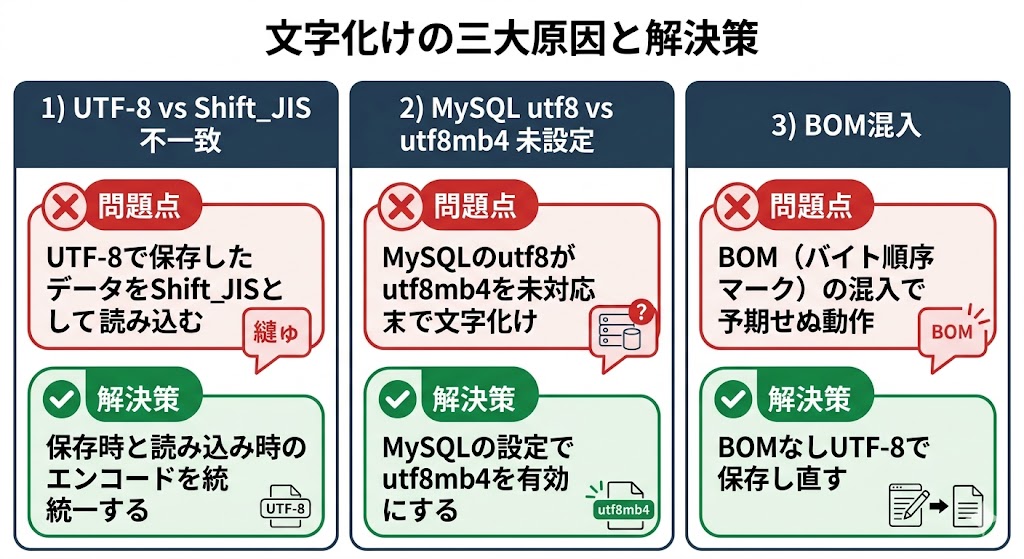
5. 文字化け三大原因と鉄則
📌 要点:現場で起きる文字化けの9割は「エンコード不一致・utf8mb4未設定・BOM混入」の3パターン。入口から出口まで UTF-8 で統一し、変換処理を極力挟まないことが根本的な解決策になる。
現場で起きる事故の9割:
- エンコード不一致(UTF-8 vs Shift_JIS)
- DB照合順序のミス(utf8mb4への未設定)
- BOMの混入(Windowsエディタでの保存)
守るべき実務の鉄則:
- 入口(フォーム)から出口(DB・出力)までUTF-8で統一する
- HTTPヘッダーで
charsetを明示する(Content-Type: text/html; charset=UTF-8) - 「変換処理」を極力挟まない(変換が増えるほど事故る)
- Windowsのメモ帳での保存は「UTF-8(BOMなし)」を選ぶ
- MySQLのテーブルとカラムのcharsetは
utf8mb4にする
FAQ:よくある質問
Q. ExcelでCSVを開くと文字化けするのはなぜですか?
ExcelはCSVをShift_JISとして開こうとする仕様のため、UTF-8で保存されたCSVは文字化けする。
対処法は2つ。
①「データ」→「外部データの取り込み」からエンコードを指定して開く、②メモ帳でファイルを開いてShift_JISで保存し直してからExcelで開く。
Q. Windowsのメモ帳でUTF-8(BOMなし)で保存するにはどうすればいいですか?
Windows 10以降のメモ帳では「名前を付けて保存」の文字コード欄で「UTF-8」を選ぶとBOMなしで保存できる(「UTF-8 BOM付き」という選択肢も別にある)。
VS CodeなどのコードエディタはデフォルトでBOMなしUTF-8が多いため、プログラミングにはエディタを使う方が安全だ。
Q. 「文字化けを直す」ツールはありますか?
オンラインツール「mojibake.com」などで変換できる。
ただし「どのエンコードで保存されているか」がわかっていれば、テキストエディタで開くエンコードを変えるだけで解決できることが多い。VS Codeなら右下のエンコード表示をクリックして「保存時のエンコードで開き直す」ことができる。
Q. UTF-16とUTF-32はどんな場面で使いますか?
UTF-16はWindowsの内部処理やJavaScriptの内部文字列表現で使われている。
UTF-32はすべての文字を4バイトの固定長で表すため処理が単純だが、英数字でも4バイト使うのでファイルサイズが膨大になる。Webや一般的なファイルの保存にはUTF-8を使うのが現在の標準だ。
Q. 日本語以外の言語でも文字化けは起きますか?
他言語でも同様に起きる。
アラビア語・中国語・韓国語など、ASCII(英数字)以外の文字を持つすべての言語で同じ問題が発生する。Unicodeがすべての言語を統一しようとしたのはこの理由からで、現在はUTF-8が事実上の世界標準となっている。
まとめ
文字化けは、同じバイト列をどう読むかという「約束」の問題だ。コンピュータは常に忠実で、人間側が「辞書(エンコード)」を揃え忘れているだけだ。
- UTF-8とShift_JISはバイト列の区切り方が異なるため、混在すると文字化けが起きる
- 「」はエラー表示、BOMは見えない地雷。どちらもエンコードの問題で直せる
- MySQLの
utf8は3バイトまで。絵文字を使うなら必ずutf8mb4に設定する - 入口から出口まで UTF-8 で統一し、変換を極力挟まないことが根本的な解決策だ
「このバイト列は、どの規約で解釈すべきか?」を常に意識できるようになれば、文字化けは恐怖の対象ではなく「制御可能な仕様」に変わる。
関連記事:128個の椅子を奪い合った「文字コード闘争史」
関連記事:幽霊文字を書くとどうなる?彁・妛の正体とJIS規格が犯した史上最大の誤植
“`

