スタックとキューの選択で迷う必要はない。
この記事でわかること:
- スタックとキューの本質的な違い(LIFO/FIFO)
- 「理論上O(1)」の裏にある物理レイヤーの差
- 循環バッファが実務最適解である理由
- Python・Javaでの正しい実装パターン
結論(最短回答)
- 戻る処理なら → スタック(LIFO)
- 順番処理なら → キュー(FIFO)
- 実務では → 標準ライブラリの Deque を使うのが最適解
重要なのは「理論計算量」だけでなく、「CPUキャッシュに優しいか?」という物理レイヤーの視点で選ぶことだ。
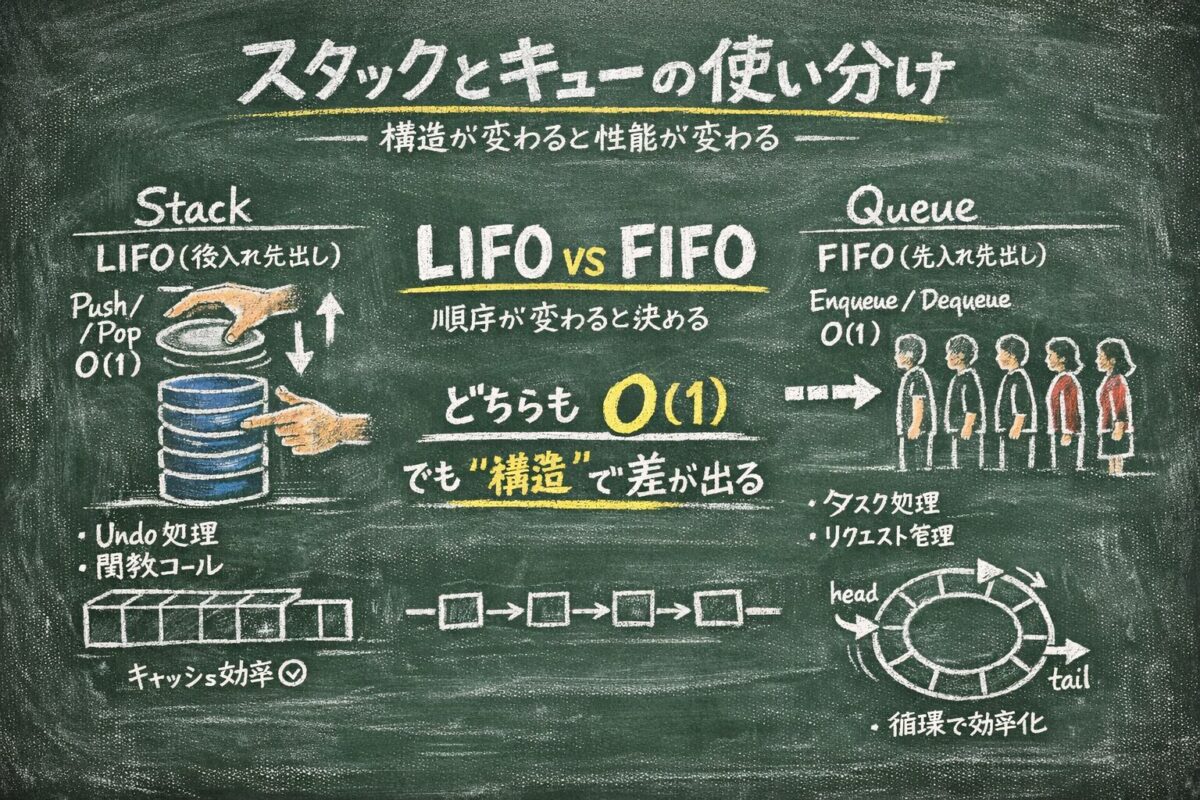
1. スタックとは?(Stack / LIFO)
📌 要点:スタックは「後入れ先出し」構造。関数呼び出し・Undo・DFSなど「直近の状態に戻る」処理に特化。実装は配列ベース一択。
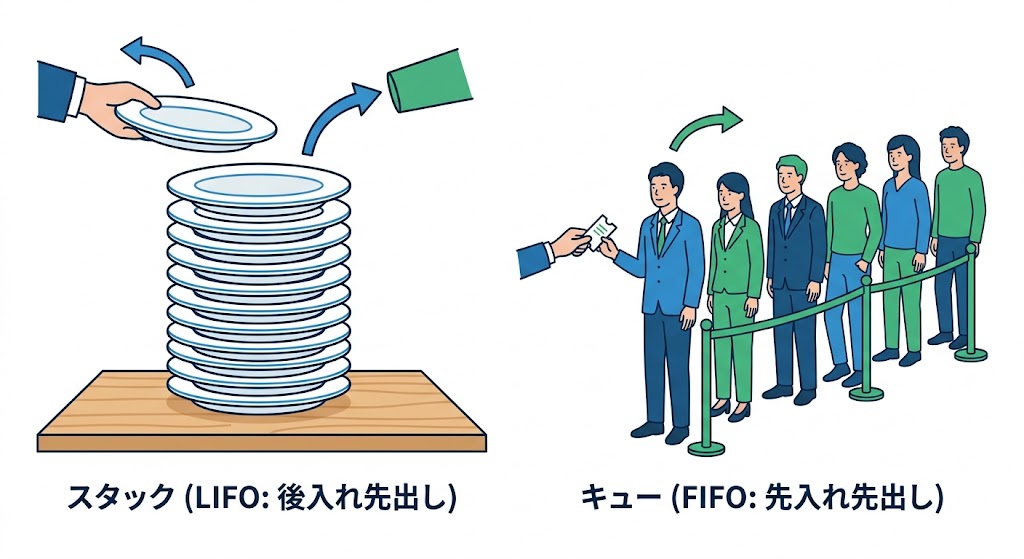
スタックは後入れ先出し(LIFO: Last-In, First-Out)構造だ。最後に入れたデータを最初に取り出す。食器の積み重ねを想像してほしい。下の皿を取りたくても、上から順に取るしかない。あれがスタックだ。
主な用途:
- Undo(元に戻す):直近の操作履歴を保持
- 関数呼び出し(コールスタック):実行地点の記録
- 深さ優先探索(DFS):行き止まりまで進み、戻る処理
- 構文解析:括弧の整合性チェック
計算量:
| 操作 | 計算量 |
|---|---|
| push(追加) | O(1) |
| pop(取り出し) | O(1) |
| 参照 | O(1) |
情シスの現場でスタックを意識するのは、障害解析のときだ。コールスタックのトレースを読めば「どの関数がどの順番で呼ばれてエラーになったか」が一目でわかる。スタックの概念を知っているかどうかで、ログ解析の速度が変わる。
2. なぜ「配列実装」が主流なのか?
📌 要点:連結リストでも実装可能だが、CPUキャッシュ効率の観点から実務では動的配列一択。メモリの連続性がパフォーマンスを左右する。
理論上は連結リストでも実装できる。しかし実務では動的配列(Array-based)一択だ。理由は3つ。
- 空間局所性:配列はメモリが連続しているため、CPUが隣接データをまとめて読み込める
- キャッシュ効率:連結リストはメモリが分散し、キャッシュミス(読み込み待ち)が発生しやすい
- メモリ効率:連結リストは各ノードに「次の住所」を示すポインタ(8〜16バイト)を保持するオーバーヘッドがある
「理論的には同じO(1)でも、なぜか遅い」というときの原因は、大抵この物理レイヤーにある。
3. キューとは?(Queue / FIFO)
📌 要点:キューは「先入れ先出し」構造。印刷ジョブ・BFS・メッセージキューなど「受信順に処理する」場面に特化。単純配列では使うな。
キューは先入れ先出し(FIFO: First-In, First-Out)構造だ。レジの行列と同じで、先に来た人から順番に処理される。
主な用途:
- タスク処理:印刷ジョブ、OSのプロセス管理
- サーバーリクエスト:受信順のパケット処理
- 幅優先探索(BFS):近いノードから順に探索
- メッセージキュー:システム間の非同期通信
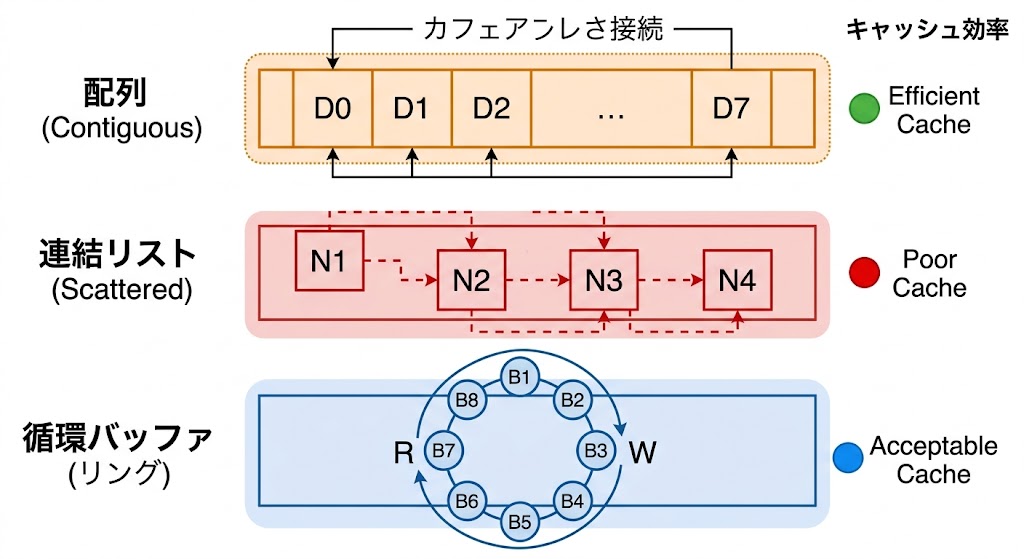
実装方式別の計算量比較:
| 実装方式 | Enqueue | Dequeue | キャッシュ効率 |
|---|---|---|---|
| 単純配列 | O(1) | O(n) | 高(ずらしコスト大) |
| 連結リスト | O(1) | O(1) | 低 |
| 循環バッファ | O(1) | O(1) | 高(実務最適解) |
単純配列でキューを実装すると、先頭要素を取り出すたびに残り全要素をずらす処理(O(n))が走る。10万件のデータで10万回の移動が発生する。これが「循環バッファ」が生まれた理由だ。
4. 実測ベンチマーク:理論が同じでも現実は違う
📌 要点:JavaでのArrayDeque vs LinkedListの比較では約1.7倍の速度差。理論計算量が同じでも物理構造の差は無視できない。
Javaで10万件のenqueue/dequeueを計測した参考値:
| 実装 | 実行時間 | 物理構造 |
|---|---|---|
| ArrayDeque | 約35ms | 配列ベース(連続メモリ) |
| LinkedList | 約62ms | 連結リスト(分散メモリ) |
約1.7倍の差。計算量が同じO(1)でも、CPUキャッシュの効率差がそのまま速度差になる。
「理論上は同じなのになぜ遅い?」は、現場でよく出る疑問だ。この答えがキャッシュ効率だと知っているだけで、パフォーマンスチューニングの切り口が変わる。
5. 優先度付きキュー・スレッドセーフ
📌 要点:重要度順の処理にはヒープ構造を使った優先度付きキューを使う。マルチスレッド環境では標準Dequeではなく専用クラスを選ぶ。
優先度付きキュー(Priority Queue):
| 構造 | 取り出し基準 |
|---|---|
| スタック | 最新のデータ |
| キュー | 到着した順序 |
| 優先度付きキュー | 設定した優先度順 |
医療システムの設計で、緊急度の高い処理から先に対応するスケジューラを実装したことがある。そこで使ったのが優先度付きキューだ。到着順ではなく「重要度×緊急度」でスコアリングして並び替える仕組みで、単純なキューでは実現できない。
スレッドセーフ性の注意:
マルチスレッド環境では標準の Deque ではなく以下を検討すること。
ConcurrentLinkedQueueBlockingQueue(生産者・消費者パターンに最適)synchronizedラッパー
6. 実装例
Python(スタック:リストをそのまま活用)
stack = []
stack.append(1) # push
stack.append(2)
print(stack.pop()) # pop -> 2Python(キュー:collections.dequeを推奨)
from collections import deque
queue = deque()
queue.append(1) # enqueue
queue.append(2)
print(queue.popleft()) # dequeue -> 1list.pop(0) でキューを実装するのは絶対NG。O(n)のコストが毎回かかる。collections.deque 一択だ。
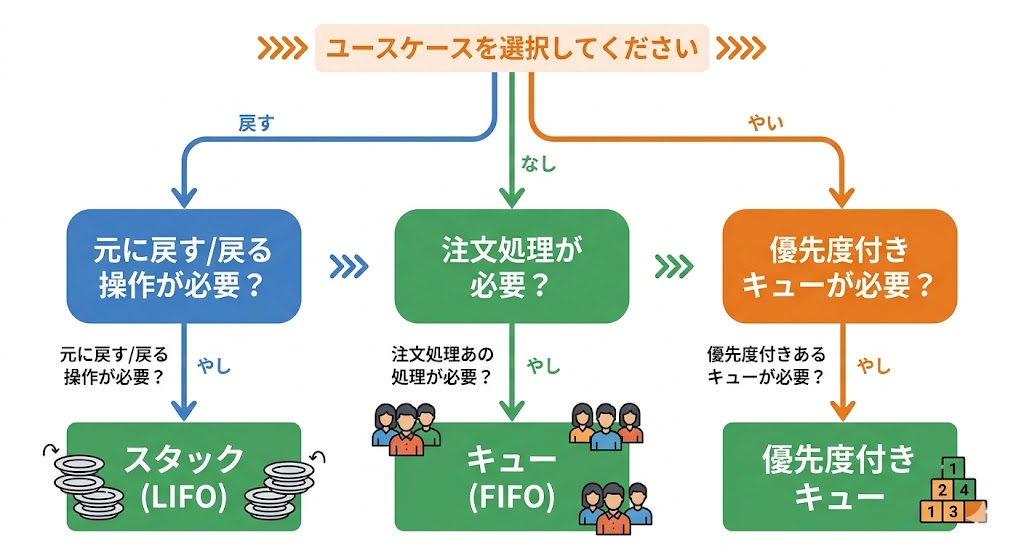
7. 迷ったときの判断フロー
- 「戻る」処理か? → スタック
- 「順番」処理か? → キュー
- 「重要度」による順序か? → 優先度付きキュー(ヒープ)
- 自作が必要か? → ほぼ不要。標準ライブラリの Deque を使う
FAQ:よくある質問
Q. どちらが高速ですか?
適切な実装(配列ベース)ならどちらもO(1)。
ただし物理メモリ配置の都合上、配列ベースがCPU効率で有利。同じ計算量でも実測値に差が出る理由はここにある。
Q. BFSとDFSで使い分ける理由は?
DFSは「一番新しく見つけた道」を突き進むためスタック、BFSは「近い順」に探索するためキューを使う。
アルゴリズムの性質がデータ構造の選択を決める。
Q. dequeとQueueの違いは?
Dequeは両端操作が可能な汎用コンテナ。
Python標準のqueue.Queueはマルチスレッドセーフな設計が主な違い。シングルスレッドならcollections.deque、マルチスレッドならqueue.Queueを選ぶ。
Q. 実務で自作すべきですか?
自作する必要はない。
標準ライブラリ(Python: deque, Java: ArrayDeque)が高度に最適化されている。自作するのは学習目的か、よほど特殊な要件がある場合だけでいい。
Q. 循環バッファはどう実装するのですか?
Pythonのcollections.deque(maxlen=N)が循環バッファの実装になっている。
maxlenを指定すると、満杯になったとき自動的に古い要素が落ちる。リングバッファが欲しい場面ではこれが最短だ。
まとめ
- スタック → 戻る処理(配列実装がベスト)
- キュー → 順番処理(循環バッファがベスト)
- 優先度付き処理 → ヒープ
- 実務 → 標準 Deque を使う
理論上の計算量だけでなく、「物理レイヤー(キャッシュ)」を意識することで現場で通用するデータ構造の選択が可能になる。「なぜ速いのか」を説明できる人間になるかどうかが、AI時代のエンジニアとしての差別化ポイントだ。
関連記事:アルゴリズムの本質は「紙とペン」に宿る
関連記事:なぜ0.1+0.2は0.3にならないのか?
“`
