
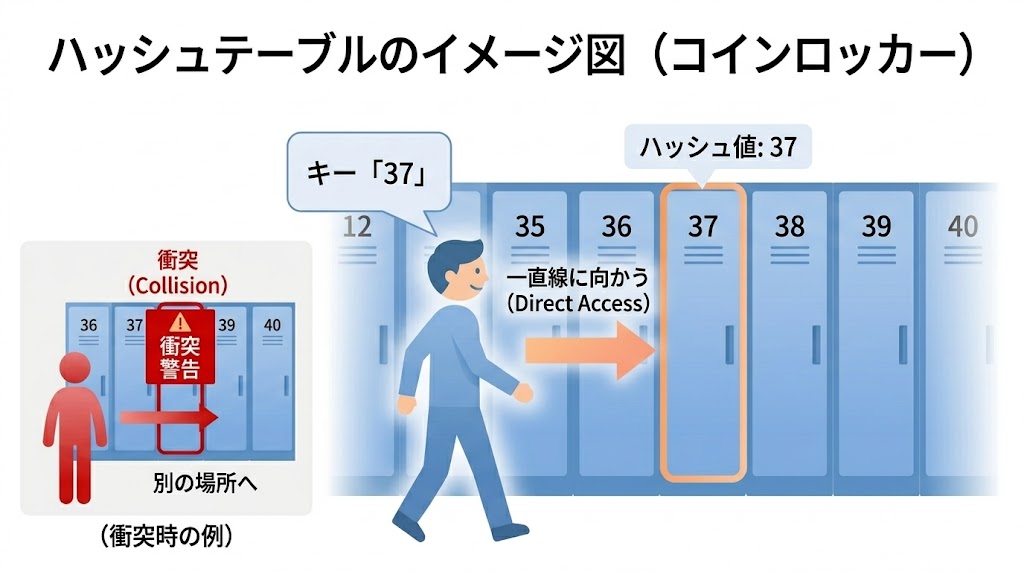
駅のコインロッカーで荷物を取り出すとき、あなたはどう動くか。
「37番に入れた」と覚えているなら、37番に一直線で向かうだけだ。100個ロッカーがあろうと、1000個あろうと、37番に行くまでの手間は変わらない。探し回る必要はない。——これがハッシュテーブルだ。
線形探索はO(n)。データが増えるほど遅くなる。でもハッシュテーブルは、100件でも100万件でもほぼ同じ速さで値を見つけられる。この「番号がわかれば一直線で行ける」仕組みを理解すると、Pythonの dict やJavaScriptのオブジェクト {} がなぜ速いのかもわかるようになる。
この記事でわかること
- ハッシュテーブルがO(1)で検索できる理由をコインロッカーの比喩で理解する
- ハッシュ関数が「何をやっているか」を具体的に把握する
- 衝突(コリジョン)が起きる原因と2つの解決策(チェイン法・開番地法)
- Pythonのdictがどう動いているか、listとの決定的な速度差
コインロッカーの仕組み:「どこに置くかを計算して決める」
📌 要点:ハッシュテーブルはキーをハッシュ関数で番号に変換し、その番号のスロットに直接アクセスする。「番号さえわかれば何件あっても一直線で行ける」のがO(1)の正体。
まず、コインロッカーがない世界を想像してほしい。
荷物を預けるとき係員に渡して、取り出すとき「サーモン色のバッグです」と言って探してもらう。荷物が100個あれば最大100個調べることになる。これが線形探索の世界だ。
コインロッカー(ハッシュテーブル)はこう考える。「預ける前に、どの番号に置くかを計算しておこう」。
キー(例:"Alice")
↓ ハッシュ関数で番号を計算
ロッカー番号(例:37番)
↓ 37番に直接アクセス
値(例:"東京オフィス・営業部")取り出すときも同じ計算をして37番に直行できる。ロッカーが100個でも1000個でも、37番に向かう手間は変わらない。これがO(1)の仕組みだ。
ハッシュ関数の役割:荷物の番号を計算して決める
📌 要点:ハッシュ関数は任意の入力を一定範囲の数値に変換する関数。同じ入力には必ず同じ番号が返る。配列サイズで余りを取ることでロッカー番号(インデックス)を決定する。
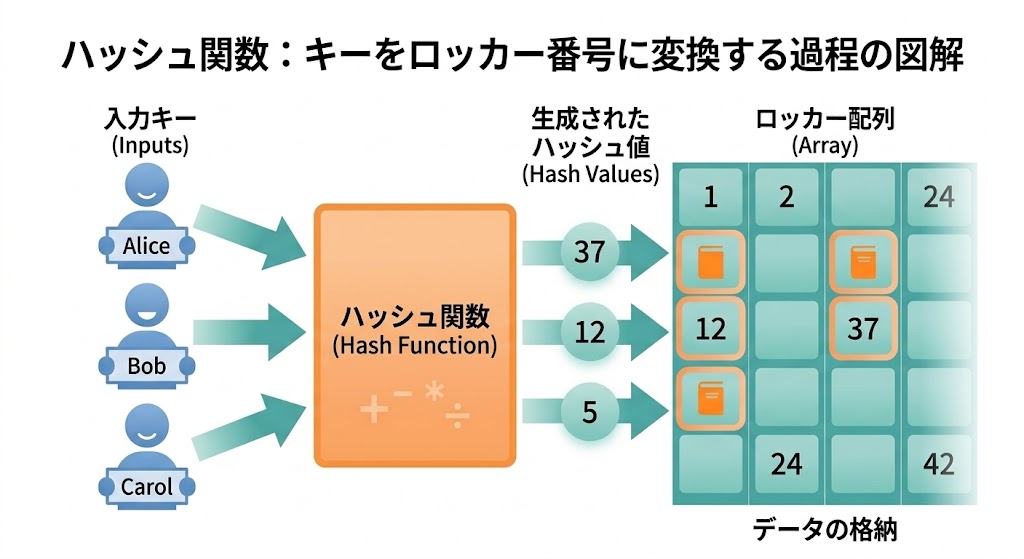
ハッシュ関数(Hash Function)は、任意のデータを一定範囲の数値に変換する関数だ。
「Alice」というキーがロッカー番号になるまでを追ってみよう。
# Pythonの組み込みhash関数
print(hash("Alice")) # → 例:-3923827347(実行環境で異なる)
print(hash("Bob")) # → 例: 1234567890
print(hash("Alice")) # → 必ず同じ値になる(同じキーは同じ番号)この大きな数値を「ロッカーの総数(配列サイズ)」で割った余り(剰余)がロッカー番号になる。
locker_count = 16
locker_number = hash("Alice") % locker_count # 0〜15のどこかに収まるハッシュ関数に求められる性質:
| 性質 | 内容 | コインロッカーで言うと |
|---|---|---|
| 決定論的 | 同じ入力→必ず同じ番号 | 同じ荷物は必ず同じロッカーへ |
| 一方向性 | 番号から元のキーは復元できない | ロッカー番号から荷物名はわからない |
| 分散性 | 異なる入力はなるべく違う番号へ | 荷物が特定ロッカーに集中しない |
| 高速性 | 計算が速い | 番号決定が一瞬で終わる |
衝突が起きたら:別のロッカーへ案内する2つの方法
📌 要点:異なるキーが同じロッカー番号になる「衝突(コリジョン)」は避けられない。チェイン法は同一スロットをリストで延長し、開番地法は別のスロットを探す。それぞれ長所と短所がある。
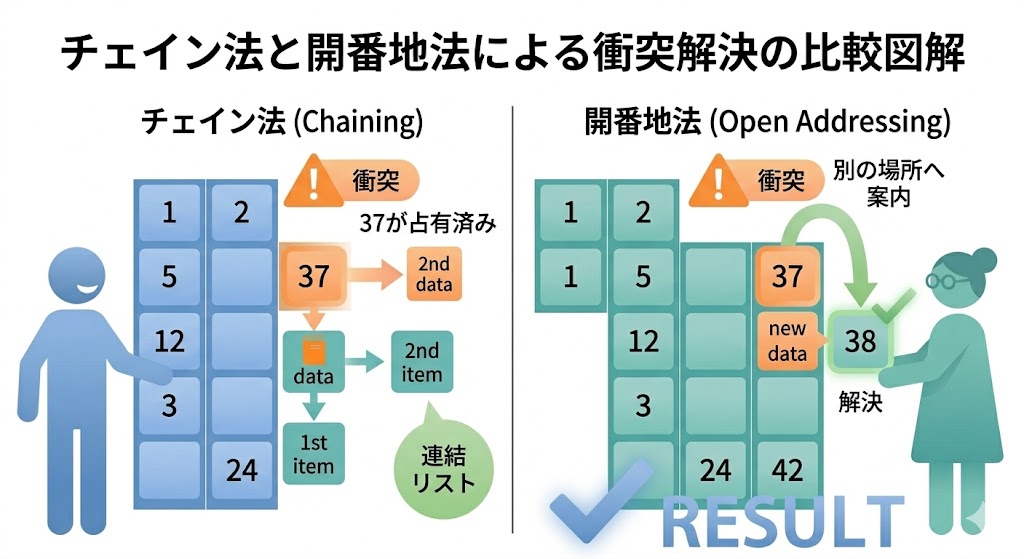
ロッカーが16個あり、キーから番号を計算する。すると当然こうなることがある。「”Alice”と”Charlie”が、偶然同じ37番になってしまった」。
これを衝突(コリジョン:Collision)という。「37番が誰かに使われてたら別の場所に回される」——コインロッカーで言えばまさにそれだ。
チェイン法(Chaining):同じ番号のロッカーに棚を追加する
衝突が起きたスロットに連結リストを置き、同じ番号になった要素を全部つなぐ方法。
ロッカー37番: ["Alice"→"東京"] → ["Charlie"→"大阪"] → NULL# チェイン法の概念をPythonで表現
hash_table = [[] for _ in range(16)] # 各スロットにリストを用意
def insert(key, value):
index = hash(key) % len(hash_table)
hash_table[index].append((key, value)) # 同じロッカーのリストに追加
def search(key):
index = hash(key) % len(hash_table)
for k, v in hash_table[index]: # ロッカー内のリストを線形探索
if k == key:
return v
return None開番地法(Open Addressing):隣の空きロッカーに入れてもらう
衝突が起きたら、空いている別のスロットを探す方法。最も単純な「線形探索法」は「詰まったら1つ後ろを試す」。
ロッカー37番: "Alice"→"東京"(先に使用中)
ロッカー38番: "Charlie"→"大阪"(37が使用中なので38へ)どちらを選ぶか
| 比較項目 | チェイン法(棚を追加) | 開番地法(隣へ移動) |
|---|---|---|
| 実装 | やや複雑(リストが必要) | シンプル |
| メモリ | 追加のポインタが必要 | スロット内で完結 |
| 高負荷時 | 比較的安定 | 急激に低下 |
| 削除 | 簡単 | 複雑(削除マークが必要) |
| キャッシュ効率 | 低め | 高め(連続メモリ) |
Pythonの dict はCPython 3.6以降、開番地法をベースにしたコンパクトな配列設計を採用している。3.7からは挿入順序の保持も保証されるようになった。
PythonのdictとlistのO(1)vs O(n):この差は現場で効いてくる
📌 要点:Pythonのdictとsetのin演算子はO(1)、listはO(n)。大量データの検索処理でこの差は決定的になる。「検索するなら辞書かセットを使う」は情シス実務でも基本ルール。
情シス部門でデータ処理スクリプトを書いていた頃、「スクリプトの処理が遅い」という相談があった。確認すると、数万件の社員リストに対して if employee_id in target_list と書いていた。target_list は普通の list だ。
list を set に1行変えるだけで、処理時間が30秒から0.5秒になった。
# O(n)の検索:リスト(コインロッカーを全部確認するようなもの)
target_list = list(range(100000))
if 99999 in target_list: # 最悪10万回の比較
print("found")
# O(1)の検索:セット(ハッシュテーブルで番号に一直線)
target_set = set(range(100000))
if 99999 in target_set: # ハッシュ計算1回で直接アクセス
print("found")Pythonでの実用ルールとして頭に入れておくべき表がこれだ。
| 操作 | list | dict / set |
|---|---|---|
in 検索 | O(n) | O(1) |
| 追加 | O(1) | O(1) |
| 削除 | O(n) | O(1) |
| インデックスアクセス | O(1) | — |
「大量データの中から何かを検索する」処理を書くなら、まず set か dict を検討する。知っているか知らないかで実行時間が100倍変わる話だ。
ハッシュテーブルが苦手なことを正直に書く
📌 要点:ハッシュテーブルはO(1)検索が得意だが、順序の保持・範囲検索・最悪ケースの劣化に注意が必要。「何でもハッシュテーブル」ではなく用途に合わせた使い分けが設計の基本。
ハッシュテーブルには不得意なことがある。正直に書く。
苦手なこと:
- ソート順での取得:ハッシュは値を散らばせるので「昇順に全件取得」はO(n log n)が必要
- 範囲検索:「年齢30〜40歳全員を取得」のような範囲クエリは不得意(二分探索木が得意)
- メモリ消費:衝突率を下げるために多めのスロットを確保するため空きが生じる
- 最悪ケース:衝突が集中するとO(n)まで劣化する(ハッシュ関数の品質に依存)
用途に合わせた使い分け:
| やりたいこと | 適したデータ構造 |
|---|---|
| キーで値を素早く引く | ハッシュテーブル(dict) |
| ソート済みで順番に取得 | 二分探索木、ソート済み配列 |
| 範囲検索(○〜○の全件) | 二分探索木、B木 |
| 先入れ先出し・後入れ先出し | キュー、スタック |
コインロッカーは「番号を知っている荷物を取り出す」のに最強だ。でも「今日預けられた荷物を全部、番号順に並べて」という処理には向いていない。道具は用途に合わせて選ぶ。
FAQ
- Qハッシュテーブルとハッシュマップは同じですか?
- A
同じ概念です。「ハッシュテーブル」はデータ構造の一般名称、「ハッシュマップ」はJavaの
HashMapなど言語特有の実装名です。Pythonではdict、JavaScriptではMapや通常のオブジェクト{}が対応します。
- Q負荷率(ロードファクター)とは何ですか?
- A
使用スロット数÷全スロット数の比率です。
コインロッカーで言えば「全ロッカーのうち何割が使用中か」です。Pythonのdictは負荷率が2/3を超えると自動的にロッカーの数を拡張(リハッシュ)します。高すぎると衝突が増え、低すぎるとメモリが無駄になります。
- Qハッシュはセキュリティにも使われると聞きましたが関係ありますか?
- A
仕組みは同じですが用途が異なります。
パスワード保存では「一方向性(ハッシュ値から元データを復元できない)」を利用します。ただし検索用ハッシュ(dictのキー)と暗号用ハッシュは品質要件が全く異なり、暗号用にはSHA-256以上が必要です。MD5は暗号用途では危険です。
- QPythonのdictは常にO(1)と考えていいですか?
- A
平均的にはO(1)ですが最悪ケースはO(n)です。
ただし実用上O(n)になる状況はほぼ発生しません。ランダムなキーを使う限り衝突が集中する確率は極めて低く、業務コードで気にする必要はほぼありません。
- QPythonのdictのキーにリストを使えないのはなぜですか?
- A
ハッシュ関数はキーが変化しないことを前提にしています。
リストは後から中身を変更できる(ミュータブル)ため、変更後にハッシュ値が変わり、対応するロッカーを見つけられなくなります。変更できない(イミュータブルな)タプルや文字列はキーに使えます。
- Q10万件のデータを毎秒何度も検索する処理があります。dictで問題ありませんか?
- A
問題ありません。
ハッシュテーブルのO(1)はデータ件数に関係しないため、10万件でも100万件でも検索速度はほぼ変わりません。高頻度で呼ばれる検索処理こそ、listからdictやsetに変える恩恵が最大になります。
まとめ
- ハッシュテーブルは「ロッカー番号を計算して直接行く」コインロッカーの仕組み
- ハッシュ関数でキーを番号に変換し、その番号のスロットにO(1)で直接アクセスできる
- 異なるキーが同じ番号になる「衝突」は避けられず、チェイン法か開番地法で解決する
- Pythonの
dictとsetのinはO(1)、listはO(n)。この差を使いこなせるかどうかが実装品質を分ける - 範囲検索・ソート順取得は不得意。目的に合ったデータ構造を選ぶのが設計の基本
コインロッカーに一直線で向かえるのは、「どこに置いたか」を番号で管理しているからだ。全ロッカーを見て回る必要はない。プログラムも同じで、「どこにあるか計算できるなら、探す必要はない」——この発想がハッシュテーブルの核心だ。
関連記事
スタックとキューなど、他の基本データ構造の使い分けはこちら。
→ スタックとキューの使い分け完全ガイド
アルゴリズムの計算量を体系的に理解したい方はこちら。
→ アルゴリズムのオーダー記法をマンガで理解する
“`

