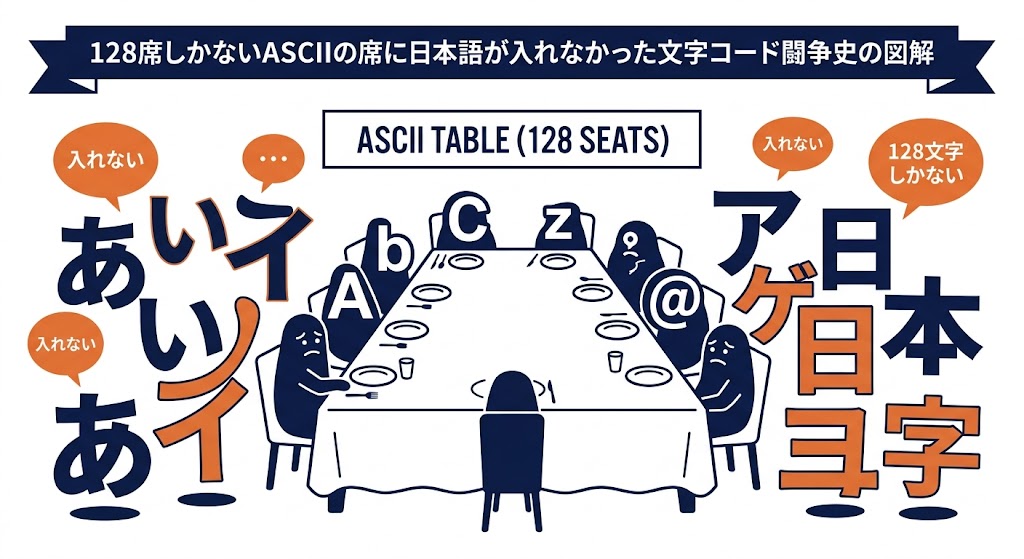
あなたが今、この画面でひらがなや漢字を読めている。実はこれ、ITの歴史においては「奇跡」に近いハックの連続によって実現されたことをご存知だろうか。
今から半世紀前、コンピュータの世界は日本語を扱うことなど想定もされていない「英語至上主義」の環境にあった。メールを送れば意味不明な記号に変わり、異なる会社のコンピュータ同士は一言も会話が通じない。そんな「万人の万人に対する闘争」が起きていた時代から、いかにして膨大な日本語の文字をデジタル世界へねじ込んだのか。
128文字という絶望的な定員制限を、人間の「脳の仕組み」にも似た驚きのトリックで突破した先人たちのドラマを解剖する。
この記事でわかること:
- 1960年代、規格が乱立し「意図しない暗号」を送り合っていた文字コードの闘争時代
- 2の7乗=128という絶対法則がなぜ英語圏以外を絶望させたのか
- 日本語に与えられた「10文字の自由枠」という絶望的な制約
- ISO IEC 2022が編み出した「モード切り替え」の革命的なハック
1. 万人の万人に対する「文字化け」闘争時代
📌 要点:1960〜70年代は各メーカーが独自の文字コードを使い、「30番は『あ』」といった約束が会社ごとにバラバラだった。データを外部に送るとゴミデータになる「文字コードの戦国時代」だった。
私たちが今、iPhoneで打った文字をAndroidで読み、Windowsで作った書類をMacで確認できるのは、世界共通の「文字コード」という約束事があるからだ。しかし1960年代から70年代初頭にかけては、そんな平和な時代ではなかった。
当時はコンピュータメーカーやソフトウェア開発者が、それぞれ勝手なルールで「30番は『あ』、31番は『い』」と決めていた。まさに「文字コードの戦国時代」だ。
自分の環境では正しく表示されても、一歩外へデータを出せば、誰にも解読できない「ゴミデータの塊」に成り下がる。哲学者ホッブズが自然状態を評した「万人の万人に対する闘争」という表現がぴったりの状況だった。
この混乱を収拾するために立ち上がったのが、アメリカの標準規格「ASCII(アスキー)」だった。しかしこれが、別の深い絶望の始まりでもあった。
2. 2の7乗の絶望。ASCIIが128文字しか持てなかった「ビットの重み」
📌 要点:ASCIIが採用した7ビット=128という制限は当時のメモリ・通信コストの現実から来ていた。大文字・小文字・数字・記号・制御文字を詰め込んだだけで128席は満席。日本語が入る余地は1ミリもなかった。
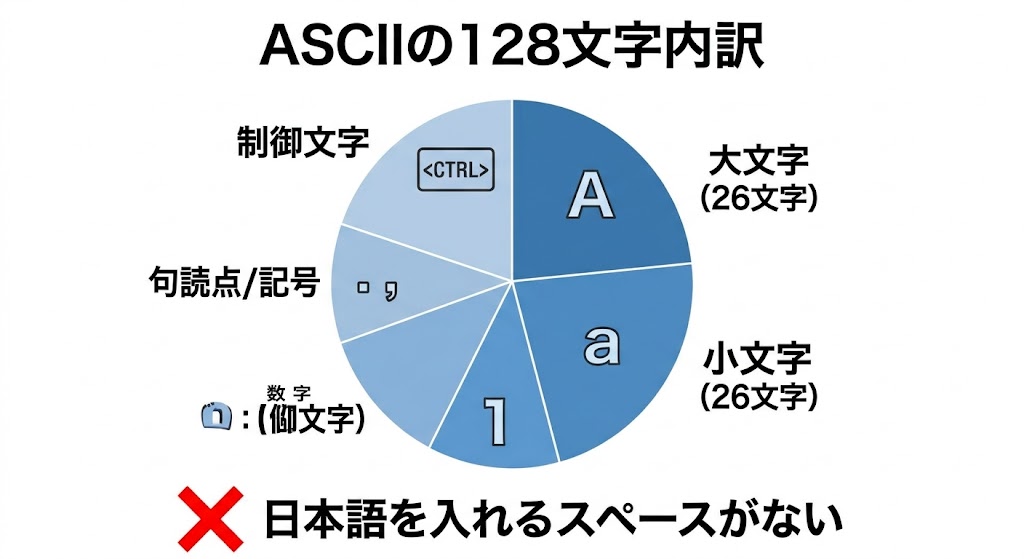
ASCIIが採用した規格は「7ビット」という単位だった。数学的に言えば 2の7乗=128。この辞書には「128個」までしか文字を登録できないという絶対的な制約だ。
128という数字は現代の視点からはあまりに矮小だ。しかし当時のメモリや通信コストは、今の数万倍も高価なものだった。1ビット増やすだけでも莫大なコスト増に繋がる時代。開発者たちは断腸の思いで「128個の椅子」に座らせるメンバーを厳選した。
ASCIIの128文字の内訳:
- 大文字アルファベット 26文字
- 小文字アルファベット 26文字
- 数字 10文字
- 記号(句読点・括弧など)
- 制御文字(改行・通信終了など機械への命令)
これらを詰め込んだだけで、128席は一瞬で満席。ひらがなや漢字を招待する余裕など、1ミリも残されていなかった。アメリカで作られたこの基準にとって、英語以外の言語、特に数千の文字を持つ日本語などは「眼中にない」存在だったのだ。
3. 「10文字やめろ!」国際規格の厳しい制限と日本語の不遇
📌 要点:ASCIIが国際規格(ISO IEC 646)へ発展した際、非英語圏に与えられた「好きに使っていい枠」はわずか10文字程度。ひらがな・カタカナ・漢字を持つ日本語にとってはデジタル世界からの「実質的な排除」に等しい宣告だった。
ASCIIがその後、国際規格(ISO IEC 646)へと発展した際、ようやく非英語圏の国々にも「自分たちの文字を入れてもいいよ」という許可が降りた。しかし条件はあまりに過酷なものだった。
各国が自由に入れ替えて使ってよいと許されたのは、128文字のうちわずか「10文字」程度。
「10文字やめろ。もうやめちまえ。そんなね。それぐらい10を開けるぐらいだったらないほうがいい」
10文字で日本語が書けるわけがない。アクセント記号付きのフランス語やドイツ語ならまだしも、ひらがな・カタカナ・漢字を抱える日本にとって、これはデジタル世界からの「実質的な排除」に等しい宣告だった。
日本のエンジニアたちはまず、エラー検出用に使っていた予備の1ビットを文字用として開放し、8ビット(256文字)へと拡張する道を選んだ。しかし256文字になっても、日本語という巨大な客人を収容するには、依然として広間が狭すぎた。
4. 脳の仕組みに学ぶ?「切り替え文字」による革命的なハック
📌 要点:ISO IEC 2022が編み出したのは「特定のマーカーが来たら、それ以降の数字の解釈をガチャンと切り替える」という動的な手法。左脳(GL)が基本文字を固定し、右脳(GR)が日本語セットをモードに応じて入れ替える。
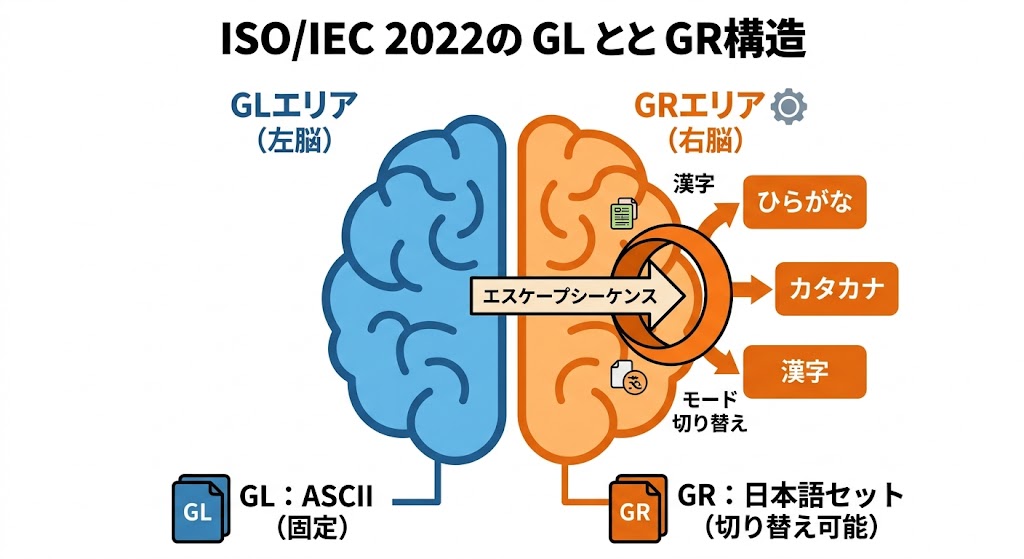
日本語という膨大な文字を、限られた256文字の枠でどう表現するか。その答えとして先人たちが編み出したのが、ISO IEC 2022で採用された「切り替え文字(エスケープシーケンス)」という魔法のようなアイデアだった。
「特定の記号(マーカー)が現れたら、それ以降の数字の割り当てをガチャンと入れ替える」という動的な手法だ。
GL(左側)領域: アルファベットなどの基本セットを固定しておく「左脳」のような領域。
GR(右側)領域: 必要に応じてひらがなやカタカナ、漢字セットを「入れ替えて」使う「右脳」のような領域。
特定のコードが流れてくると、コンピュータは「ここからはカタカナモードだな!」と判断し、同じ数字でも全く別の文字として解釈を切り替える。
一文字に一つの番号を固定するという常識を捨て、「モードを切り替える」という時間軸の概念を持ち込むことで、狭い256文字という枠を何倍にも活用することに成功した。これが日本語がデジタル世界に「ねじ込まれた」瞬間だった。これを考えた人は天才を通り越して変態的(褒め言葉)だと思う。
5. 切り替えハックの代償:なぜ「文字化け」は消えないのか
📌 要点:「切り替えの合図(マーカー)」が通信途中で消えると、コンピュータは今どのモードにいるかを見失い迷子になる。これが日本の「文字化け問題」の最大の根本原因だった。
この「ガチャン」という鮮やかな入れ替えには、致命的な弱点があった。
もし通信の途中で「切り替えの合図(マーカー)」が消えてしまったらどうなるか。コンピュータは今、自分が「アルファベットモード」なのか「日本語モード」なのかを見失い、迷子になってしまう。その結果として現れるのが、あの無慈悲な「文字化け」だ。
この複雑な切り替え構造こそが、長年日本のエンジニアを苦しめ続けてきた文字化け問題の最大の原因だった。私たちが手にした利便性は、先人たちが薄氷を踏むようなハックを積み重ねた上に成り立つ、危ういバランスの結果だったのだ。
FAQ:よくある質問
Q. 現在は文字コードの問題は解決されたのですか?
大幅に改善されたが完全には解決されていない。
Unicodeというすべての言語を統一する規格が普及し、UTF-8が事実上の世界標準になったことで、新しいシステム間での文字化けは激減した。しかし古いShift_JISで保存されたレガシーデータは今も現場に残っており、移行作業での文字化けは2026年現在でも定期的に発生している。
Q. Unicodeが普及したのにShift_JISがまだ使われている理由は?
主に2つの理由がある。
①1990〜2000年代に構築された日本のレガシーシステム(基幹業務システム・金融系・行政系)がShift_JISで構築されており、移行コストが膨大。
②Windowsの旧来の日本語環境がShift_JISをデフォルトにしていた歴史的経緯がある。
Q. JISコードとShift_JISは同じですか?
JISコードとShift_JISは異なる。
JISコード(JIS X 0208)は文字集合の定義。Shift_JISはそのJISコードをASCIIと共存できるよう特殊なビットシフトで符号化した方式だ。「JIS」と「Shift_JIS」は混同されやすいが、文字集合と符号化方式という別の概念だ。
Q. EUC-JPとはどういう規格ですか?
EUC(Extended Unix Code)-JPはUNIX系システムで日本語を扱うために使われた符号化方式だ。
同じJIS X 0208の文字集合を使いながらもバイト列の生成方法がShift_JISと異なる。現在はUTF-8に置き換えられているケースがほとんどだ。
Q. 他の言語はASCIIの問題をどう解決しましたか?
A. 西洋言語(フランス語・ドイツ語等)はアクセント記号付き文字がせいぜい数十種類なので、ASCII拡張(ISO 8859シリーズ)でなんとか対応できた。アラビア語・ヘブライ語は右書きという追加の複雑性があり、中国語・韓国語は日本語と同様に数千の文字を持つため同じ苦労をした。これがUnicodeという「全言語統一規格」が生まれた根本的な動機だ。
まとめ
文字化けは単なるバグではない。それは、限られたリソースの中で自分たちの文化や言語を後世に残そうとした、エンジニアたちの「闘いの跡」だ。
- 1960年代は規格が乱立し、通信が「意図しない暗号」になる文字コードの闘争時代だった
- 世界標準ASCIIはわずか128文字しかなく、英語圏以外を想定していない不平等なスタートだった
- 日本語対応には「10文字の自由枠」という絶望的な制約があった
- 特定のコードでモードを切り替える「切り替え文字」の発明により、限られた枠を何倍にも活用することに成功した
次にスマホで文字を打つとき、その一文字一文字が128個の椅子を奪い合った歴史の果てにあることを少しだけ思い出してほしい。現代の当たり前は、過去の「変態的」なまでの執念によって支えられている。
関連記事:文字化けの正体|UTF-8とShift_JISの衝突をバイト列で見る
関連記事:幽霊文字を書くとどうなる?彁・妛の正体とJIS規格が犯した史上最大の誤植

