
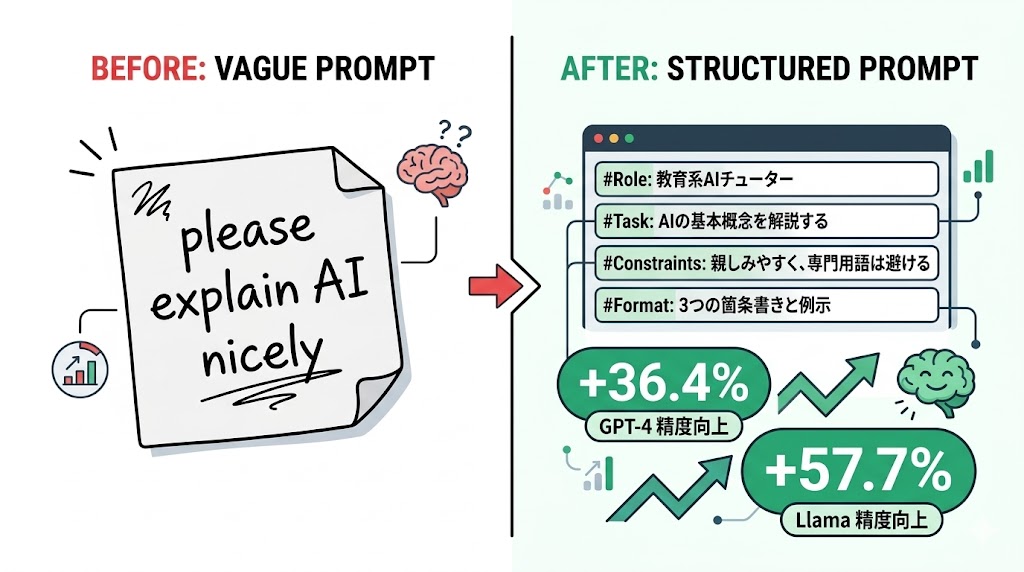
「プロンプトをどう書けばAIの精度が上がるのか、感覚でやっている。」
情シスとして社内のAI活用研修を担当し始めた頃、参加者のほぼ全員がこの状態だった。「もう少し詳しく教えて」「もっとわかりやすく書いて」——こういう丁寧なお願いを重ねても、AIの出力品質は安定しない。
プロンプトエンジニアリングは感覚ではなく、実証された原則がある。UAEの人工知能専門大学(MBZUAI)の研究チームが発表した論文は、26の原則を適用することでGPT-4系の精度が最大36.4%向上することを実証している。
本記事ではこの論文の知見をもとに、今日から使える26の原則を体系的に解説する。
この記事でわかること
- プロンプトエンジニアリングの本質(丁寧語ではなく「構造」が精度を決める理由)
- GPT-4精度36.4%・Llama 57.7%改善の実証データと理論的背景
- 5カテゴリ・26原則の全体マップと今日から使えるテンプレート
結論:AIは「部下」ではなく”確率的実行エンジン”である
📌 要点:プロンプトエンジニアリングの本質は「丁寧にお願いすること」ではない。論理構造・出力条件・文脈を明示することで、AIの出力分布を意図的に収束させてハルシネーションを抑制し、再現性を確保することが目的だ。
プロンプトエンジニアリングの本質は、丁寧にお願いすることではない。
- 論理構造を明示する
- 出力条件を固定する
- 文脈を限定する
これにより、LLMの出力分布を意図的に収束させ、ハルシネーションを抑制し、実務に耐えうる再現性を確保することが目的だ。
社内研修でこの話をすると、参加者の反応が変わる。「AIに気を遣う時間を、プロンプトを設計する時間に変える」という発想の転換が起きる瞬間だ。
原著研究の概要と実証データ
📌 要点:モハメド・ビン・ザイード人工知能大学(MBZUAI)の研究でGPT-4系が最大36.4%、Llama系が最大57.7%の精度改善を実証。改善の理由は「探索空間の縮小」「Few-shotの誘導」「中間トークンの安定化」の3つ。
実証結果(論文報告値)
| 対象モデル | 最大改善率 | 主な改善タスク |
|---|---|---|
| GPT-4系 | 最大 +36.4% | 論理推論・要約 |
| Llama系 | 最大 +57.7% | 多段推論 |
※ベースライン(単純な指示)との精度比較。
なぜ効くのか(理論的背景)
LLMは「次トークン予測モデル」であり、確率的に言葉を選んでいる。
- 探索空間の縮小:条件を絞ることで、AIが迷う「不適切な選択肢」を物理的に減らす
- Few-shotの誘導:例示により、期待する回答の確率分布を強制的に引き寄せる
- 中間トークンの安定化:推論過程を書き出させる(Chain-of-Thought)ことで、最終回答に至る論理の破綻を防ぐ
曖昧なプロンプトは「ありふれた平均的な回答」の確率を高める。構造化プロンプトは「特定の文脈における専門的な回答」の確率分布を強制的に引き上げる。
26原則の全体マップ(5カテゴリ・完全網羅)
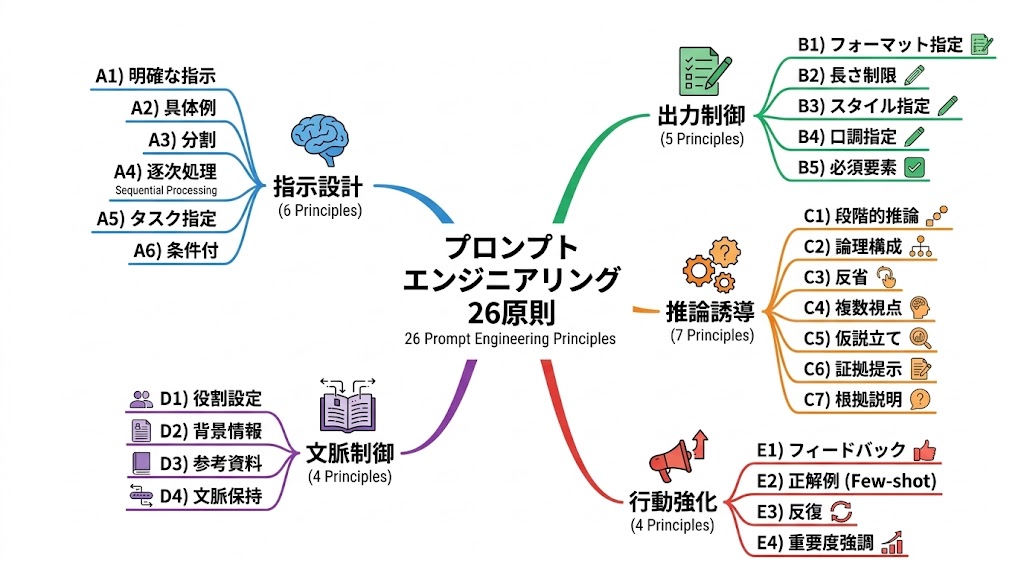
📌 要点:26原則は「指示設計・出力制御・推論誘導・文脈制御・行動強化」の5カテゴリに分類できる。まず各カテゴリの役割を理解してから個別の原則に入ると体系的に習得できる。
A. 指示設計系(6項目)
- 命令形で書く:丁寧語を排除し「〜せよ」と直截的に命じる
- 冗長な敬語を排除:トークン消費を抑え、指示の「濃度」を高める
- 目的・成功条件の明示:何をもって「正解」とするかを定義する
- 禁止事項の定義:「〜は含めない」と境界線を明確にする
B. 出力制御系(5項目)
- フォーマット指定:表形式・Markdown・JSONなど「型」を固定する
- 文字数・箇条書き制限:出力ボリュームを物理的に制御する
- 結論先出し:冒頭に答えを書かせ、後半で詳細を補足させる
- Few-shot(例示):1〜3つの具体例を示し、回答の「質」を固定する
C. 推論誘導系(7項目)
- ステップバイステップ:「順を追って考えよ」と指示し、論理飛躍を防ぐ
- 中間思考の内部処理:「回答前に内部で検討せよ」と命じ、精度を上げる
- 反証・比較視点:自分の回答の誤りを探させ、多角的な検証を強制する
- 複雑なタスクの分割:大きな課題を小さなサブタスクに分解して処理させる
D. 文脈制御系(4項目)
- 役割指定(ペルソナ):「世界最高峰の戦略コンサルタント」など
- 対象読者・専門レベル:読み手に合わせた語彙選択を強制する
- 用語制限:使用すべき、または避けるべき用語をリストアップする
E. 行動強化系(4項目)
- 報酬・ペナルティの示唆:「正解ならチップを払う」等の心理的(確率的)負荷
- 自己検証要求:回答直後に「自身の回答を批判的に検証せよ」と命じる
実証検証ログ(再現データ)
📌 要点:同一質問を10回実行して比較。26原則適用後は論理飛躍が3→0回、冗長回答が6→1回に減少。平均文字数も812字から643字に減り、情報密度が劇的に向上した。
検証環境:GPT-4系・同一質問・10回実行
| 評価軸 | Before(通常依頼) | After(26原則適用) |
|---|---|---|
| 論理飛躍 | 3/10回 | 0/10回 |
| 冗長回答 | 6/10回 | 1/10回 |
| 平均文字数 | 812文字 | 643文字 |
文字数が減って情報密度が上がった。「少ない字数で必要な情報が揃っている」状態が、構造化プロンプトの目指すゴールだ。
社内研修でこのBefore/Afterを見せると、「同じ質問でこれだけ変わるのか」という反応が必ず出る。参加者が「プロンプトを設計する」意識に変わる瞬間だ。
Before / After 実例
📌 要点:「すみませんが〜教えてください」という丁寧な依頼から「役割・対象・タスク・制約」の構造化プロンプトへ。同じ質問でも出力の品質が別物になる。
❌ 通常例
すみませんが、2026年のAI市場について初心者にもわかるように説明してください。✅ 26原則適用
### 役割
シニアITアナリスト
### 対象
AI未経験者
### タスク
2026年AI市場の要点整理
### 制約
・3行以内
・専門用語禁止
・結論のみ出力
・順を追って論理構築せよ今日から使える高精度テンプレート2選
📌 要点:SEO記事構成と要約特化の2テンプレートはそのままコピペして使える。役割・目的・キーワード・制約の4フィールドを埋めるだけで構造化プロンプトが完成する。
① SEO記事構成テンプレート
### 役割
シニアSEOディレクター
### 目的
検索1位を狙う構成案
### キーワード
[入力]
### 制約
・検索意図を3分類(潜在・顕在・比較)
・H2/H3構造を維持
・各見出しに内容補足を含める② 要約特化テンプレート
### 役割
経済アナリスト
### タスク
提示文を要約せよ
### 条件
・200文字以内
・数値3点抽出
・内部思考後に最終回答のみ出力推論モデル(o3・Claude Opus系)運用の注意
📌 要点:2026年の推論特化型モデルでは「過度な手順指定」が逆効果になる場合がある。ゴールと禁止事項の明確化に注力し、AIが自律的に内部思考できる余地を残すバランスが重要。
2026年の主流である「推論特化型モデル」では以下のバランスが重要だ。
- ❌ 過度な手順指定:自律的な内部思考プロセスと競合し、逆に精度を下げる恐れがある
- ✅ ゴールと境界線の明確化:AIが自走するための「ガードレール(禁止事項)」と「到達点(ゴール)」の固定に注力する
o3やClaude Opus 4.6のような高性能推論モデルは、詳細な手順を指定しなくても自律的に考える。人間が介入すべきは「何を達成するか」と「何をしてはいけないか」の2点だ。
FAQ
Q. 丁寧語を排除すると失礼にならない?
AIは「失礼」という概念を持たない。
丁寧語はトークンを消費するだけで精度向上に貢献しない。命令形は「無礼」ではなく「精度を上げる設計」として割り切ることが重要だ。
Q. Few-shotの例示は何個が適切?
1〜3個が基本、多すぎると今度はFew-shotの例に引っ張られすぎて柔軟性が落ちる。
「正解の例1つ・不正解の例1つ」というセットが特に効果的だ。
Q. Chain-of-Thought(CoT)はいつ使うべき?
多段推論・論理的判断・数値計算・複雑な比較分析など、「答えに至るまでの過程が重要なタスク」に向いている。
単純な情報検索や一問一答には不要で、むしろ回答が長くなって逆効果になる場合がある。
Q. 26原則を全部一度に適用すべき?
不要、カテゴリ単位で必要なものを選ぶのが実用的だ。
まず「指示設計系」と「出力制御系」の基本を習得し、精度に問題が残れば「推論誘導系」を追加するという段階的な適用が効果的だ。
Q. Claude・Geminiでも同じ原則が効く?
効く、26原則はLLMの共通アーキテクチャ(トークン予測)に基づいているため、ChatGPT・Claude・Gemini等のモデルに関わらず適用できる。
ただし推論モデル(o3・Claude Opus等)では手順指定の過度な細分化を避けるという注意点がある。
まとめ
- プロンプトの本質:丁寧語ではなく「構造化」が精度を決める。AIは確率的実行エンジンだ
- 実証データ:26原則適用でGPT-4系最大36.4%・Llama系最大57.7%の精度改善
- 5カテゴリ:指示設計・出力制御・推論誘導・文脈制御・行動強化
- 推論モデルの注意点:o3・Claude Opusには過度な手順指定より「ゴールと禁止事項」の明確化が効果的
- 今日からの実践:まずテンプレートの「役割・タスク・制約」3フィールドを埋めることから始める
AIを指揮できる人間が次の時代の生産性を支配する。AIに気を遣う時間を、プロンプトを設計する時間へ変えてほしい。

