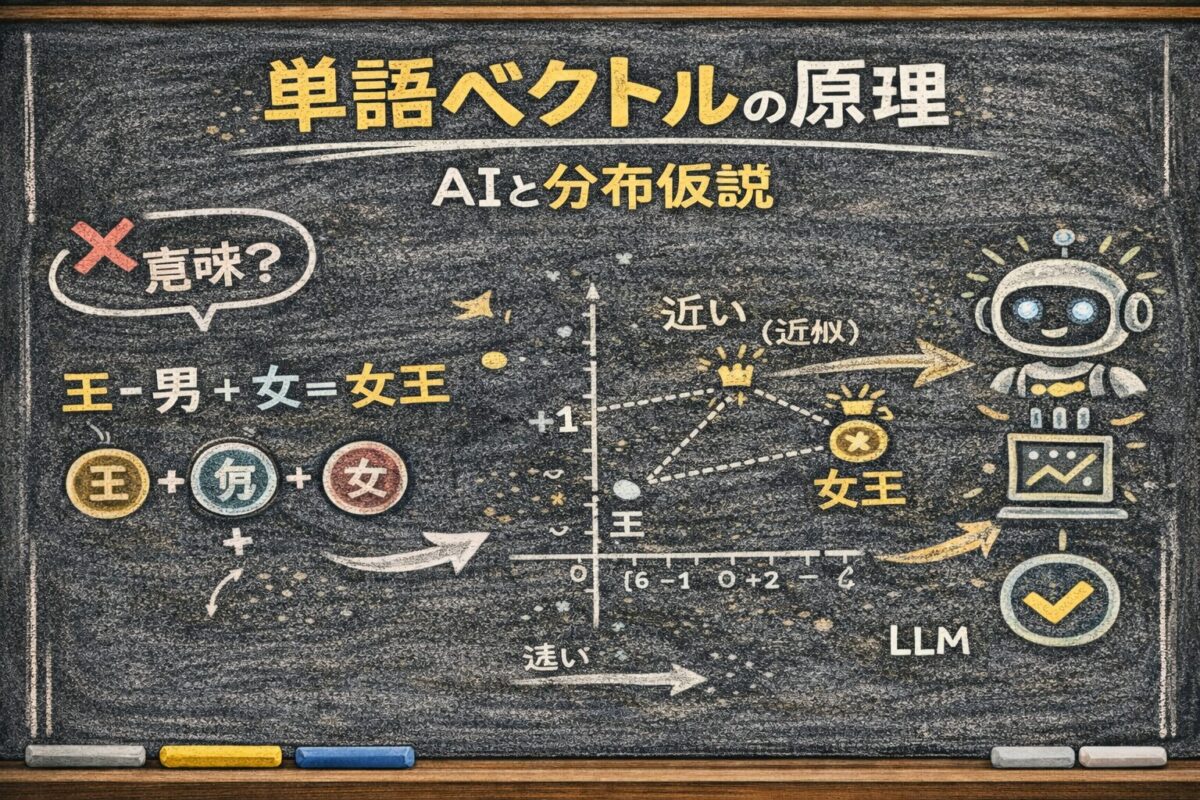

なぜAIは「王 − 男 + 女 = 女王」のような計算ができるのか?
この疑問に答える鍵が Word Embeddings(単語埋め込み) だ。ChatGPTやClaudeなど、現代の大規模言語モデル(LLM)の知性の根底に流れる考え方でもある。
「AIが言葉を理解している」と感じる場面は多い。しかし実際のところ、AIは「意味を理解している」のではなく、意味の構造を数学的に写し取っているのだと私は考えている。この違いを理解するかどうかで、AIツールの使い方が変わってくる。
情シスとして大量のシステム設計に関わってきた立場から言うと、AIを業務に導入するときに最も重要なのは「AIが何をしていないか」を理解することだ。Word Embeddingsの仕組みはその理解の出発点になる。
この記事でわかること:
- 「王−男+女=女王」が成立する数学的な理由
- AIが言葉を「数値(ベクトル)」に変換する仕組み
- Word2Vec・GloVe・FastTextの違いと進化の方向
- 古典的なWord Embeddingsの限界と現代LLMへの繋がり
1. 分布仮説:意味は「隣の席」で決まる
📌 要点:「似た文脈で使われる単語は意味も似ている」という分布仮説が、Word Embeddingsの理論的支柱。AIは辞書ではなく「周辺の単語の統計」から意味を推論している。
Word Embeddingsの理論的支柱は、言語学者J.R.ファースが提唱した分布仮説(Distributional Hypothesis) だ。
「似た文脈で使われる単語は、意味も似ている」
AIは辞書を読まない。代わりに、膨大なテキストを眺めて「どの単語がセットで現れやすいか」の統計を取る。
「犬」と「猫」は、どちらも「飼う」「可愛い」「餌」「散歩」といった共通の単語に囲まれて出現する。AIはこの「周辺環境の類似性」から、両者が近い意味を持つと推論するのだ。

辞書で「犬:哺乳類の一種。ペットとして飼われる……」という定義を読み込んでいるわけではない。単語の「付き合い」から関係性を学習している。これが分布仮説の核心だ。
2. なぜ単語をベクトルにするのか?
📌 要点:AIは文字列を計算できないため、単語を多次元空間上の「座標(ベクトル)」に変換する。意味が似ている単語ほど、この空間内での物理的な距離が近くなる。
AIにとって文字列は「ただの記号」だ。文字列のままでは計算ができない。
そこで、単語を多次元空間上の座標、つまり「ベクトル」に変換する。3次元空間なら「犬 = (0.2, 0.8, 0.4)」のような数値の組み合わせで表現される(実際には300〜1000次元を使う)。
意味が似ている単語は、この巨大な空間内でも物理的な距離(コサイン類似度)が近くなるように配置される。これにより、曖昧な「意味」を「距離と方向」という数学的対象として扱えるようになる。
分かりやすく言えば、「犬」と「猫」はこの空間内で近い場所に配置され、「犬」と「銀行」は遠い場所に配置される。「近さ=意味の類似度」という変換だ。
3. ベクトル演算が「概念」を表現できる理由
📌 要点:「王−男+女≈女王」が成立するのは、ベクトル空間内に「性別方向」や「王族方向」といった意味の軸が自然に形成されるから。
有名な計算式「王 − 男 + 女 ≈ 女王」が成立するのは偶然ではない。
Word Embeddingsは学習の過程で、空間内に特定の「意味方向」を形成する。
- 性別軸:男 → 女への方向(方向と長さが一定)
- 王族軸:一般人 → 王への方向
ベクトル空間において、「男から女へ」の差分と「王から女王へ」の差分がほぼ同じ方向と長さを指すようになる。つまり、ベクトルの差分が「概念の差」そのものを記述しているのだ。
「日本」→「東京」と「フランス」→「パリ」の差分も同様に一致する。AIは「首都とはその国の行政中心地である」という定義を教わっていない。ただ「首都の名前と国の名前がセットで登場する」というパターンを統計から学習した結果として、この関係が空間内に浮かび上がってくる。
4. 代表的な学習モデル:Word2Vecとその進化
📌 要点:Word2Vec・GloVe・FastTextは「どうやってベクトル空間を構築するか」のアプローチが異なる。FastTextは文字単位での分解により未知語にも対応できる。
AIがどのようにしてベクトル空間を構築するか。手法は大きく3つに分類される。

| モデル | 手法の核心 | 特徴 |
|---|---|---|
| Word2Vec | 中心単語から周囲を予測(Skip-gram等) | 実装がシンプル・高速 |
| GloVe | 単語の共起確率をグローバルな統計行列として処理 | 大規模コーパスに強い |
| FastText | 単語をさらに細かい「文字の塊」に分解して処理 | 未知語・表記ゆれに対応 |
学習の数理的な直感
学習の本質は「文脈予測の的中率を最大化すること」だ。AIは意味を教わっているわけではない。隣り合う単語を当てるゲームを繰り返した「副産物」として、精緻な意味構造が空間内に浮かび上がるのだ。
これは試験勉強に例えると分かりやすい。単語の意味を暗記するのではなく、大量の例文を読み込んで「文脈から意味を推測する」練習を繰り返した結果、自然に語彙力がついていく感覚に近い。
5. Word Embeddingsの限界と現代のLLM
📌 要点:古典的なWord Embeddingsは多義語の文脈依存処理が弱い。BERTやGPT等の現代LLMはトークンごとに文脈に応じた動的な座標を生成することでこの限界を突破した。
古典的なWord Embeddings(静的表現)には、大きな弱点があった。
① 多義語に弱い
「バンク」(銀行 or 土手)が同じ座標に固定されてしまう。文脈によって「川のバンク」と「銀行のバンク」を区別できない。
② 文脈依存性が低い
文全体の流れを無視して、単語単体で意味が決まってしまう。「彼は走った」の「走った」と「彼の考えは走っている」の「走った」が同じベクトルになる。
この限界を「文脈によってリアルタイムに座標を書き換える」ことで突破したのが、BERTやGPTなどの文脈依存型モデル(動的表現) だ。
同じ単語でも、文章の前後関係によって毎回異なるベクトルが割り当てられる。ChatGPTやClaudeが「文脈を理解している」と感じられる理由はここにある。静的なWord Embeddingsの発展系として、現代LLMの意味処理能力は飛躍的に向上した。
FAQ:よくある質問
- Q次元数(300次元、1000次元等)はなぜそんなに多いのですか?
- A
意味の「細かいニュアンス」を捉えるには、それだけ多くの軸が必要だからだ。3次元では「性別・王族・生物か無生物か」程度しか区別できないが、300次元あれば「感情・時代・文化的背景・専門分野」など、より豊かな関係性を表現できる。
- QWord Embeddingsは日本語にも使えますか?
- A
使える。日本語の場合は「分かち書き」(形態素解析)が必要になる点が英語との違いだ。MeCabやSudachiで単語に分解してから学習させる。日本語版Word2VecやBERTの事前学習済みモデルも公開されている。
- QChatGPTが使っている技術はWord Embeddingsとは別物ですか?
- A
Word Embeddingsはその前身・構成要素の一つだ。GPTはTransformerというアーキテクチャを使い、文脈に応じた動的なベクトルを生成する。「単語を数値に変換して意味を計算する」という本質的な発想はWord Embeddingsから受け継いでいる。
- QAIが「意味を理解した」と言えるのはどの時点からですか?
- A
難しい哲学的問いだ。現時点では「意味の構造を数学的に模倣している」と言う方が正確だろう。ただし模倣の精度が人間の判断を超えるケースが増えており、「理解」と「模倣」の境界は曖昧になりつつある。
- Qコサイン類似度とはどういう計算ですか?
- A
ベクトル同士の「向きの近さ」を-1〜1で表す指標だ。
1に近いほど意味が似ており、-1に近いほど意味が対照的、0に近いほど無関係であることを示す。距離(ユークリッド距離)ではなく「向き」で測る理由は、ベクトルの大きさ(出現頻度の影響)を排除するためだ。
まとめ
Word Embeddingsの核心は3点に集約される。
- 単語の意味は「周囲に誰がいるか(文脈・関係性)」で決まる
- 関係性は「多次元空間上の距離と方向」として表現できる
- ベクトルの演算によって、概念の操作が可能になる
AIは「意味を理解している」のではなく、意味の構造を数学的に写し取っている。このロジックを知ることで、AIの得意なこと・苦手なことの輪郭が見えてくる。AIツールを業務に活かしたいなら、まずその「知性の正体」を理解することから始めることをお勧めしたい。
関連記事:最新AIモデル比較と基本:業務効率を最大化する「使い分け」の正解
関連記事:なぜ0.1+0.2は0.3にならないのか?IEEE 754の正体と実務の回避策
“`

