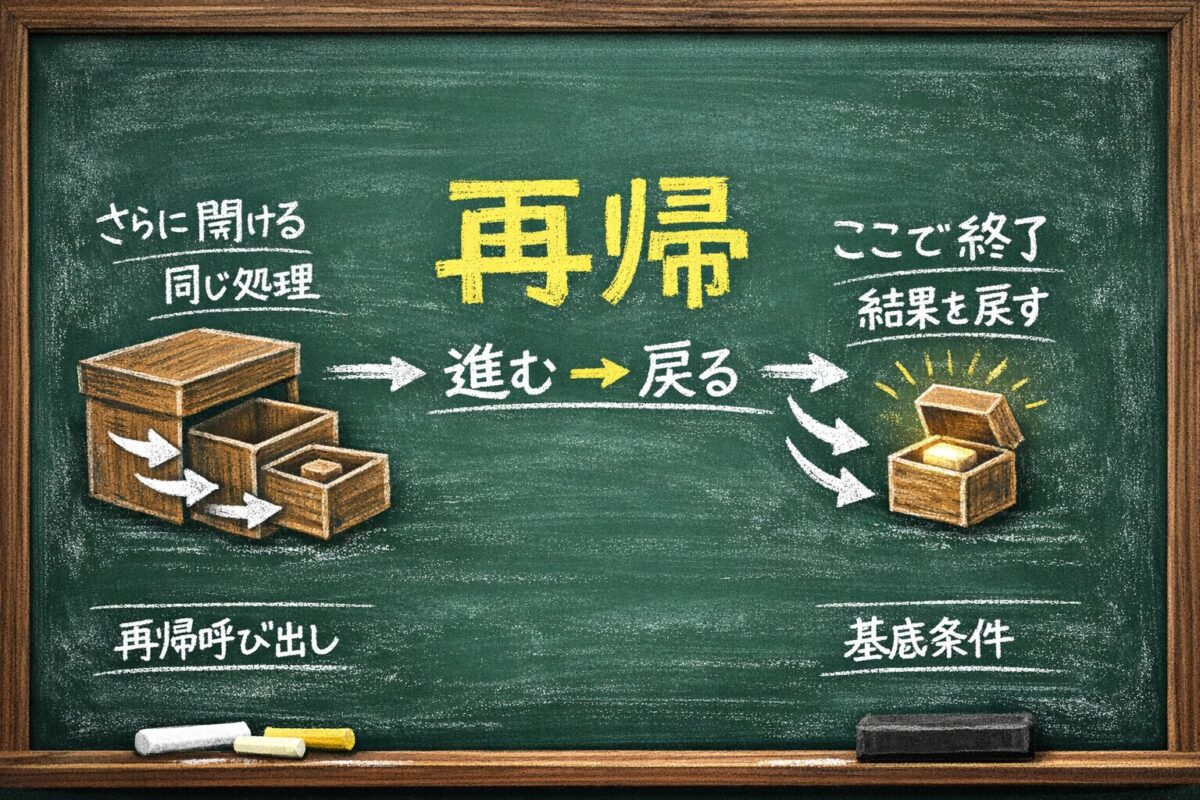
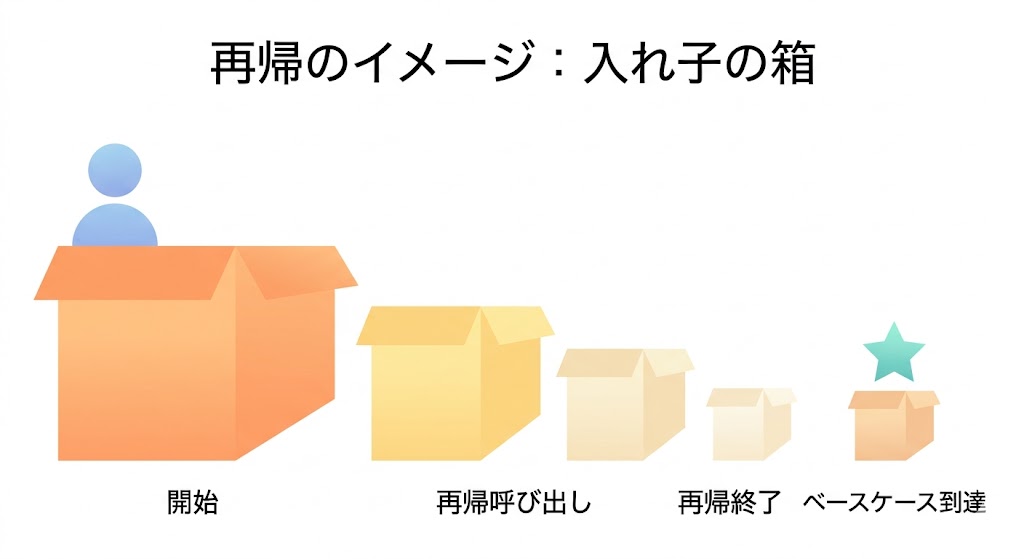
プレゼントの箱を開けたら、中にまた箱があった。その箱を開けたら、またさらに箱があった。それを繰り返して、ようやく一番小さい箱の中にプレゼントが入っていた——。
この「箱の中に箱があり、一番小さい箱に辿り着くまで開け続ける」という構造が、再帰の本質だ。
再帰(さいき)とは、関数が自分自身を呼び出す仕組みのことだ。「え、自分で自分を呼ぶ?」と感じるのは正常な反応だ。初めて見ると不思議に思う。でも一度イメージが掴めると、「これを再帰で書けばすっきりする」という場面がはっきり見えるようになる。
この記事でわかること
- 再帰の仕組みを「入れ子の箱」の比喩でゼロから理解する
- 再帰に必ず必要な「止まる条件(基底条件)」の役割
- 再帰がどのように呼び出しを積み重ねて戻ってくるか
- Pythonでの基本的な実装例と、よくある落とし穴
再帰の基本:「もう一度同じことをやる」と「止まる条件」
📌 要点:再帰は「自分自身を呼び出す」部分と「呼び出しを止める条件(基底条件)」の2つだけで成り立つ。止まる条件がないと永遠に呼び出し続けてプログラムがクラッシュする。
再帰を理解するには、2つだけ覚えれば十分だ。
| 要素 | 役割 | 入れ子の箱で言うと |
|---|---|---|
| 再帰呼び出し | 自分自身を呼び出す | 「また箱があった。開けよう」 |
| 基底条件(ベースケース) | 呼び出しを止める条件 | 「一番小さい箱に辿り着いた。プレゼントがある。終わり」 |
この2つがセットになって初めて再帰は動く。基底条件がないと、箱を開け続けて永遠に終わらない——プログラムで言えば無限ループと同じで、最終的にエラーになる。
一番シンプルな例を見てみよう。「3, 2, 1, 発射!」のカウントダウンだ。
def countdown(n):
# 基底条件:0になったら終わり
if n == 0:
print("発射!")
return
# 今の数を表示して、1小さい数で自分自身を呼ぶ
print(n)
countdown(n - 1) # ← ここで自分を呼んでいる
# 実行
countdown(3)
# 出力:
# 3
# 2
# 1
# 発射!countdown(3) は countdown(2) を呼び、countdown(2) は countdown(1) を呼び、countdown(1) は countdown(0) を呼ぶ。countdown(0) で「0になった」という基底条件に引っかかって終わる。
なぜ動くのか:呼び出しが積み重なって戻ってくる
📌 要点:再帰呼び出しは「コールスタック」に積み重なる。基底条件に達すると積んだ順とは逆に解消されていく。「積み上げて、折り返して、戻ってくる」というイメージが再帰の動作の本質。
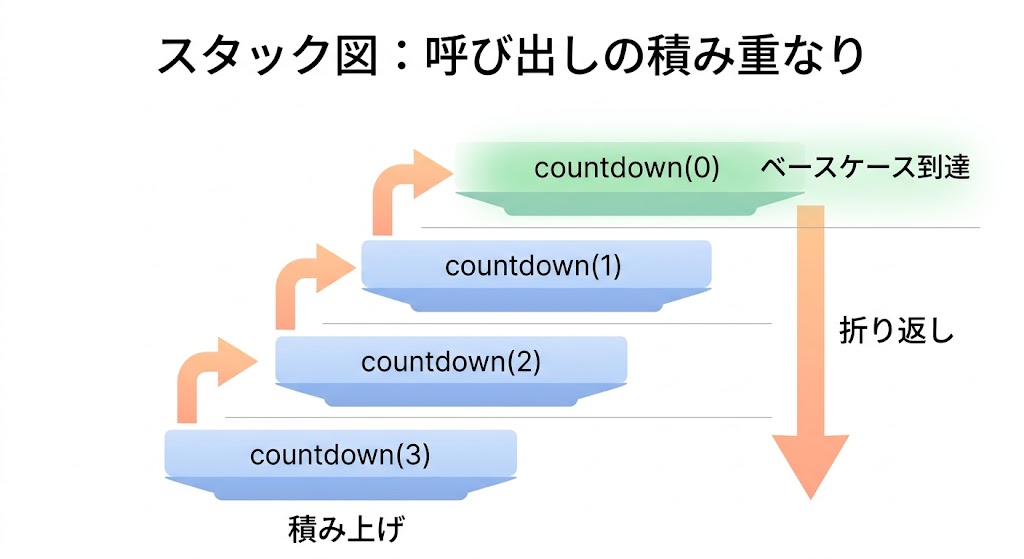
「自分が自分を呼ぶのに、なんで終わるの?」という疑問は正しい。ここを理解するとすっきりする。
コンピュータは関数を呼び出すたびに「今どこにいるか」の情報をスタックという場所に積み上げていく。お皿を1枚ずつ重ねていくイメージだ。
countdown(3) の場合、こう積み重なる:
【積み上げフェーズ】
countdown(3) を呼ぶ → スタックに積む
└─ countdown(2) を呼ぶ → スタックに積む
└─ countdown(1) を呼ぶ → スタックに積む
└─ countdown(0) を呼ぶ → スタックに積む
└─ 基底条件に到達!「発射!」と表示して終了基底条件に到達したあとは、積んだ逆順に解消されていく:
【戻りフェーズ】
countdown(0) が終わる → スタックから取り出す
countdown(1) が再開して終わる → スタックから取り出す
countdown(2) が再開して終わる → スタックから取り出す
countdown(3) が再開して終わる → スタックから取り出す
全部終わり ✅「積み上げて、折り返して、戻ってくる」——これが再帰の動作だ。入れ子の箱を全部開けてプレゼントを見つけたら、来た道を戻るのと同じだ。
実際に動かしてみる:階乗の計算
📌 要点:n の階乗(n!)は「n × (n-1) × (n-2) × … × 1」の計算。「n! = n × (n-1)!」という自分自身を含む定義があり、再帰との相性が非常に良い。
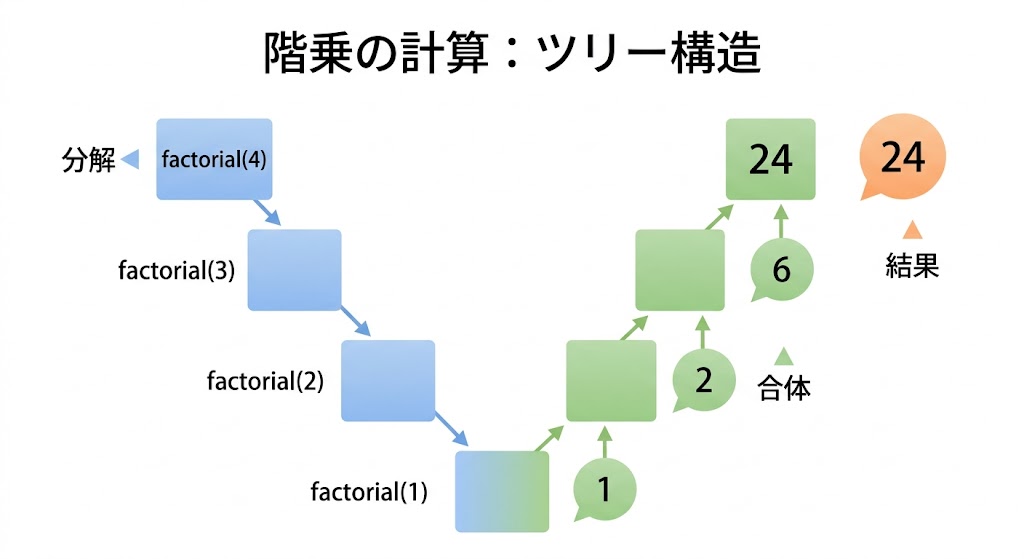
階乗(かいじょう) とは「その数以下の全整数をかけ合わせた結果」だ。
- 4の階乗(4!)= 4 × 3 × 2 × 1 = 24
- 3の階乗(3!)= 3 × 2 × 1 = 6
- 1の階乗(1!)= 1 = 1
ここで気づくことがある。4! = 4 × 3! だ。3! = 3 × 2! で、2! = 2 × 1! だ。つまり「nの階乗 = n × (n-1)の階乗」という構造がある。これが再帰と相性抜群な理由だ。
def factorial(n):
# 基底条件:1の階乗は1(これ以上は分解しない)
if n == 1:
return 1
# n の階乗 = n × (n-1) の階乗
return n * factorial(n - 1) # ← 自分より少し小さい問題として自分を呼ぶ
# 実行例
print(factorial(4)) # → 24
print(factorial(5)) # → 120factorial(4) がどう動くかを追ってみよう:
factorial(4) = 4 × factorial(3)
↓
factorial(3) = 3 × factorial(2)
↓
factorial(2) = 2 × factorial(1)
↓
factorial(1) = 1 ← 基底条件!
<戻りフェーズ>
factorial(1) = 1
factorial(2) = 2 × 1 = 2
factorial(3) = 3 × 2 = 6
factorial(4) = 4 × 6 = 24 ✅「大きな問題(4!)を小さな問題(3!)に渡して、最終的に一番小さい問題(1!)に到達する」——入れ子の箱を開け続けて、一番小さい箱でプレゼントを見つける構造と同じだ。
よくある落とし穴:終わらない再帰
📌 要点:基底条件を忘れる・基底条件に到達しない設計をすると無限に呼び出しが続きエラーになる。「この関数はどこで止まるか」を必ず先に考えてから書くと安全。
再帰で一番多いミスが「止まらない再帰」だ。
# ❌ 悪い例:基底条件がない
def countdown_bad(n):
print(n)
countdown_bad(n - 1) # 0になっても止まらず、マイナスに突入し続ける
# countdown_bad(3) を実行すると...
# 3, 2, 1, 0, -1, -2, -3 ... 永遠に続く
# → 最終的に RecursionError: maximum recursion depth exceededPythonはデフォルトで再帰の深さを1000回に制限している。1000回を超えると RecursionError が出て止まる。エラーが出たときに気づけるのはまだいい方で、「気づかずにすごく深い再帰を書いてしまう」ミスが実際には多い。
安全に書くためのコツ:
# ✅ 良い例:基底条件を先に書く
def countdown_good(n):
if n <= 0: # ← 基底条件を先に書く(0以下になったら必ず止まる)
print("発射!")
return
print(n)
countdown_good(n - 1)再帰を書くとき、「この関数はどこで止まるか」を先に決めるのが鉄則だ。基底条件を先に書いてから再帰呼び出しを書く、という順番を守れば、止まらない再帰の大半は防げる。
再帰が向いている問題・向いていない問題
📌 要点:「問題を同じ構造の小さな問題に分解できる」ものは再帰と相性が良い。ただし、単純なループで書ける処理を再帰にするのは可読性と効率の面で逆効果になることがある。
再帰が向いている場面:
- 木構造やフォルダ構造の探索:フォルダの中にフォルダがある。その中にもフォルダがある——この入れ子構造は再帰と相性が良い
- マージソート・クイックソート:「半分に分けて同じ処理をする」はそのまま再帰になる
- 数学的な帰納的定義:階乗・フィボナッチ数列など「n番目 = n-1番目を使って定義できる」問題
ループで書いた方がいい場面:
- 単純な繰り返し処理(1から100まで足す、など)
- データ件数が多く再帰が深くなりすぎる場合
- パフォーマンスが最優先の処理
実は、再帰で書けるものは必ずループでも書ける。どちらが「読みやすいか」で選ぶのが正しい判断だ。
情シス部門でファイルサーバーの棚卸しスクリプトを書いたとき、「フォルダの中にあるファイルを全部列挙する」処理に再帰を使った。フォルダの深さが事前にわからない(3段のこともあれば10段のこともある)ような処理では、再帰が圧倒的に自然に書けた。ループで書こうとすると何段分かを先に決めておく必要が生じて、かえって複雑になる。
FAQ
- Q再帰と「ループ(for文・while文)」は何が違いますか?
- A
どちらも「繰り返し処理」です。
ループは「何回繰り返すか」が明示的で、繰り返しの状態を変数で管理します。再帰は「問題を小さい問題に渡す」構造で、繰り返しの状態が関数の引数として表現されます。どちらでも同じ処理を書けますが、木構造の探索など「深さが事前にわからない」問題では再帰の方がすっきり書けることが多いです。
- Q「RecursionError: maximum recursion depth exceeded」というエラーが出ました。何ですか?
- A
Pythonのデフォルトの再帰上限(約1000回)を超えたエラーです。
原因は①基底条件がない、②基底条件に到達しない設計、③データが深すぎる、のいずれかです。まず基底条件の設計を見直してください。sys.setrecursionlimit(n)で上限を変更できますが、根本的な設計を直す方が安全です。
- Q再帰は遅いと聞きましたが本当ですか?
- A
部分的に正しいです。
関数呼び出しのたびにスタックフレームを積む処理が発生するため、単純なループより少しオーバーヘッドがあります。ただし、マージソートのように「アルゴリズムの設計自体が再帰的な問題」では、再帰の方が速かったりコードが読みやすかったりするため一概に「遅い」とは言えません。
- Q再帰の「基底条件」は必ず1つですか?
- A
いくつでも構いません。
条件が複数ある場合は複数書けます。たとえばフィボナッチ数列では「n=0のとき0を返す」「n=1のとき1を返す」と2つの基底条件を持ちます。
- Qマージソートの記事で出てきた再帰と、この記事の再帰は同じものですか?
- A
同じ仕組みです。
マージソートのmerge_sort関数が自分自身を呼んでいる部分がまさに再帰で、「1要素になったら返す」が基底条件にあたります。今回の記事の知識があれば、マージソートのコードがより自然に読めるはずです。
- Q「末尾再帰」という言葉を見かけました。通常の再帰と何が違いますか?
- A
末尾再帰とは「再帰呼び出しが関数の最後の操作になっている」再帰です。
一部の言語やコンパイラは末尾再帰をループに最適化でき、スタックを増やさずに実行できます。Pythonは末尾再帰最適化を行わないため、Pythonを使う限りは通常の再帰と同じスタック消費になります。
まとめ
- 再帰とは関数が自分自身を呼び出す仕組み。「入れ子の箱を一番小さい箱まで開け続ける」動作そのもの
- 必ず基底条件(止まる条件)が必要。これがないと永遠に呼び出し続けてエラーになる
- 呼び出しはコールスタックに積まれ、基底条件で折り返して逆順に解消される
- 木構造・フォルダ探索・マージソートなど「同じ構造の小さい問題に分解できる」問題と相性が良い
- 再帰を書くときは「どこで止まるか」を先に決めるのが鉄則
「自分で自分を呼ぶ」という発想は最初は不思議に感じる。でも一度「入れ子の箱を開けて戻ってくる」というイメージが掴めると、再帰を見たときに「ああ、また箱の中に箱があるやつだ」と自然に読めるようになる。
関連記事
再帰を使って「分けて整列して合体させる」マージソートはこちら。
→ マージソートとは?書類を分けて合体で理解するO(n log n)
アルゴリズムの計算量を体系的に理解したい方はこちら。
→ アルゴリズムのオーダー記法をマンガで理解する
“`

