
バラバラに混ざった100枚の書類を1人で並び替えるのは大変だ。
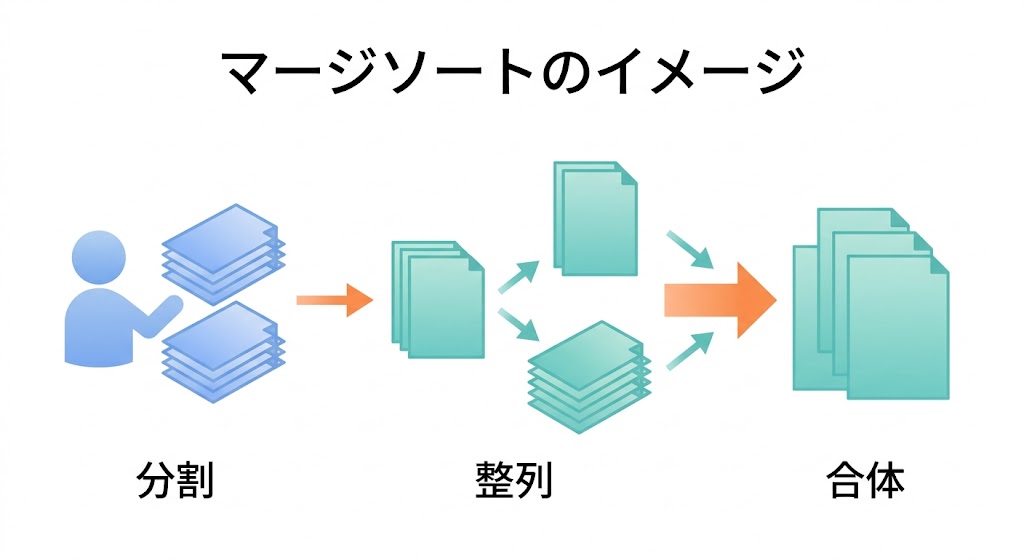
でも「半分に分けて、それぞれ並び替えてから合体させる」という発想に切り替えると話が変わる。50枚ずつ2人に分担して、最後に合体させれば済む。さらに「50枚も多すぎる」なら、また半分に分ければいい。1枚になるまで分け続けて、1枚ずつ比べながら正しい順に合体させる——これがマージソートだ。
「分割して統治する(Divide and Conquer)」というアイデアが土台にある。難しそうな言葉だが、要するに「大きな問題を小さく分けて、小さい問題をひとつずつ解いて、最後にくっつける」だ。
この記事でわかること
- マージソートの動作を書類の分割・合体の比喩でステップごとに理解する
- O(n log n)が「どこから来るのか」を数字で把握する
- 他のソートとの違いと、マージソートを選ぶべき場面
- Pythonでのシンプルな実装コード
分けて、分けて、合体する:動作をステップで追う
📌 要点:配列を半分に分割することを1要素になるまで繰り返す(分割フェーズ)。1要素は「それ自体がすでに整列済み」。あとは2つの整列済み配列を先頭から比べながら合体させる(マージフェーズ)を繰り返す。
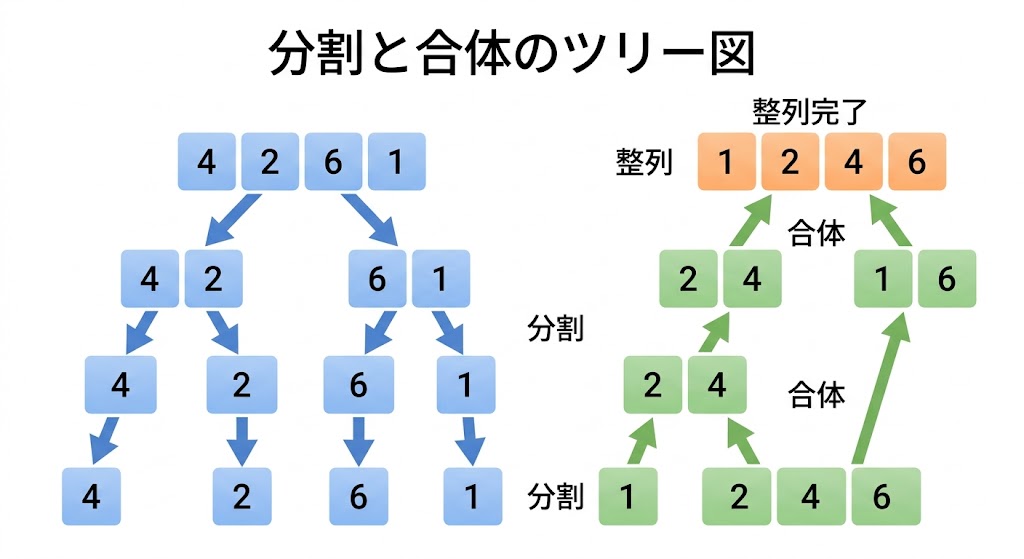
[4, 2, 6, 1] を例にしよう。書類が4枚、バラバラに混ざっている状態だ。
フェーズ1:とにかく1枚になるまで分ける
[4, 2, 6, 1]
↓ 半分に分ける
[4, 2] [6, 1]
↓ さらに半分に分ける
[4] [2] [6] [1]1枚になった。1枚の書類はそれだけで「整列済み」だ。 これが分割の終点だ。
フェーズ2:比べながら合体させる(マージ)
2枚ずつ合体させるとき、こう動く。
[4] と [2] を合体:
→ 4と2を比べる: 2が小さい → 2を先に置く
→ 残った4を置く
→ 完成: [2, 4]
[6] と [1] を合体:
→ 6と1を比べる: 1が小さい → 1を先に置く
→ 残った6を置く
→ 完成: [1, 6]次に [2, 4] と [1, 6] を合体する。
[2, 4] と [1, 6] を合体:
→ 先頭同士を比べる: 2 vs 1 → 1が小さい → 1を置く
→ 先頭同士を比べる: 2 vs 6 → 2が小さい → 2を置く
→ 先頭同士を比べる: 4 vs 6 → 4が小さい → 4を置く
→ 残った6を置く
→ 完成: [1, 2, 4, 6] ✅全ステップをまとめると:
| フェーズ | 操作 | 状態 |
|---|---|---|
| 分割① | 半分に分ける | [4,2,6,1] → [4,2] / [6,1] |
| 分割② | さらに半分に分ける | [4]/[2] / [6]/[1] |
| マージ① | 2枚ずつ合体 | [2,4] / [1,6] |
| マージ② | 2束を合体 | [1,2,4,6] |
「分けながら下に降り、合体しながら上に戻る」——木の枝が広がって戻ってくるようなイメージだ。
Pythonで実装すると
少し長く見えるが、やっていることは「分ける関数」と「合体する関数」の2つだけだ。
def merge_sort(arr):
# 1要素以下なら分割終了(そのまま返す)
if len(arr) <= 1:
return arr
# 真ん中で半分に分ける
mid = len(arr) // 2
left = merge_sort(arr[:mid]) # 左半分を再帰的にソート
right = merge_sort(arr[mid:]) # 右半分を再帰的にソート
# 2つの整列済み配列を合体させる
return merge(left, right)
def merge(left, right):
result = []
i = j = 0 # 左配列・右配列それぞれの先頭を指す番号
# 両方に要素がある間、先頭同士を比べて小さい方を取り出す
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 残った要素をそのままつなぐ(すでに整列済みなので比較不要)
result.extend(left[i:])
result.extend(right[j:])
return result
# 実行例
arr = [4, 2, 6, 1, 3, 5]
print(merge_sort(arr)) # → [1, 2, 3, 4, 5, 6]merge_sort の中で merge_sort を呼んでいる部分(「再帰」という仕組み)が初めて見る場合は少し不思議に感じるかもしれない。「自分が終わるまで自分を呼び続け、1要素になった時点で止まる」——これは別記事で詳しく解説しているので、ここでは「こういう書き方ができる」と覚えておけば十分だ。
O(n log n)とは何か:分割の回数×各段の作業量
📌 要点:分割の段数はlog₂n回(データが半分になる回数)。各段でのマージ作業はn回。掛け合わせてO(n log n)になる。データが2倍になっても増加は「1段増えるだけ」なのでO(n²)より圧倒的に速い。
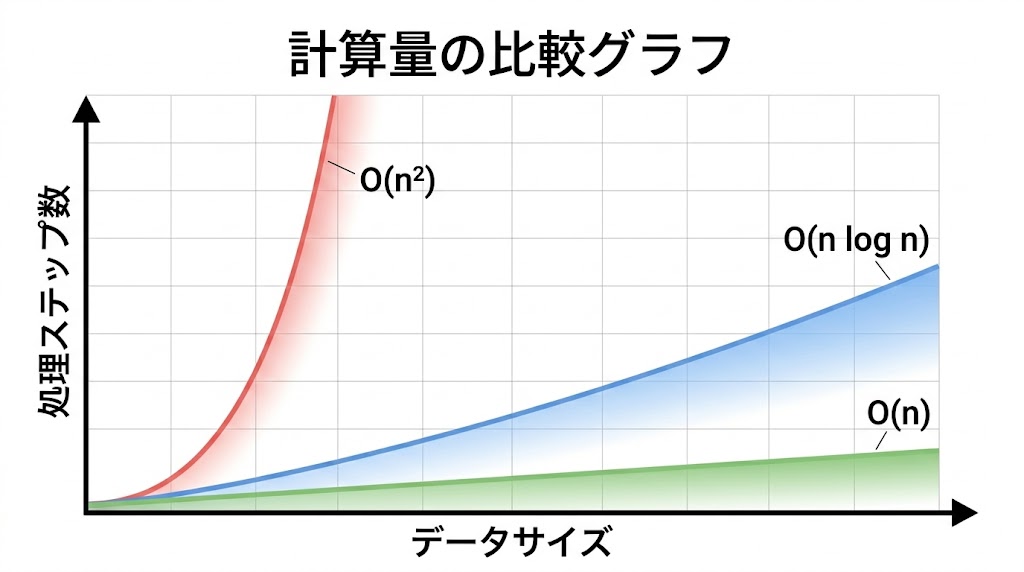
マージソートの計算量は O(n log n) だ。この「n log n」がどこから来るのかを確認しよう。
分割の段数:log₂n 段
8枚の書類を1枚になるまで半分に分けると何段かかるか。
8枚 → 4枚 → 2枚 → 1枚
1段 2段 3段8 = 2³ なので3段。16枚なら4段、100万枚なら約20段。「2で何回割ると1になるか」がlog₂nだ。
各段のマージ作業:n 回
どの段でも、全要素を1回ずつ比べてマージしていく。合計の比較回数はその段でのn回になる。
掛け合わせると:n × log n = O(n log n)
| データ件数 | 分割段数 | 合計作業量の目安 | バブルソートO(n²)との比較 |
|---|---|---|---|
| 8件 | 3段 | 約24回 | 56回 |
| 1,000件 | 10段 | 約10,000回 | 約500,000回 |
| 100万件 | 20段 | 約20,000,000回 | 約500,000,000,000回 |
100万件のデータで、バブルソートの25,000倍速い。これがO(n log n)の威力だ。
マージソートの強みと弱み
📌 要点:マージソートは「常に安定したO(n log n)」が最大の強み。最悪ケースがないためデータの状態に左右されない。弱みは「合体のために別の配列を用意するメモリ消費」で、O(n)の追加メモリが必要になる。
マージソートはすごいアルゴリズムだが、弱点も正直に書く。
強み:
- 最悪ケースがO(n log n)。クイックソートは最悪O(n²)になることがあるが、マージソートはどんなデータでも安定してO(n log n)を保つ
- 安定ソート。同じ値の要素の元の順序が保たれる(後で説明する「安定性」が重要な場合に使える)
- データの状態に左右されない。整列済みでも逆順でも常に同じ速さ
弱み:
- 追加のメモリが必要。マージするとき「合体後を置く別の配列」が必要なため、O(n)分の追加メモリが発生する。元の配列だけで完結するクイックソート(in-place)と比べると不利な場面がある
- 小さいデータでは遅い。8件以下程度では、準備のオーバーヘッドが挿入ソートに負けることがある(PythonのTimsortが小さい部分配列に挿入ソートを使うのはこの理由)
| 比較項目 | マージソート | クイックソート |
|---|---|---|
| 平均計算量 | O(n log n) | O(n log n) |
| 最悪計算量 | O(n log n) | O(n²) |
| 追加メモリ | O(n)必要 | O(log n)で少ない |
| 安定性 | ✅ 安定 | ❌ 不安定 |
| 小データへの強さ | △ | ◎ |
| 大データへの安定性 | ◎ | △(最悪ケースのリスクあり) |
「最悪の場合でも速さが保証される」ことが重要なシステムではマージソート、平均速度を最大化したい場合はクイックソート——という使い分けが一般的だ。
実務で見かけるマージソートの場面
📌 要点:外部ソート(ディスク上の大量データ整列)にはマージソートが使われる。ファイルを分割して部分的に整列後に合体させる仕組みが、まさにマージソートの考え方そのもの。
情シス部門でデータベースの移行作業を担当したとき、数百万件のレコードを日付順に並び替える処理が必要になったことがある。メモリに全件乗らないため、ファイルを分割してそれぞれ整列し、最後に合体させる方式をとった。これはまさにマージソートの考え方だ。
データベースの ORDER BY 句の内部でも、ディスク上の大量データを並び替える「外部ソート」にはマージソートの手法が使われている。「分けて、整列して、合体」という発想は、メモリの制約を超えた大量データ処理の基本パターンになっている。
FAQ
- Qマージソートの「マージ」とはどういう意味ですか?
- A
マージ(merge)は「合体させる」「統合する」という意味です。2つの整列済み配列を1つの整列済み配列に合体させる操作を指します。「ファイルをマージする」「ブランチをマージする」というIT用語も同じ意味で使われています。
- Qマージソートはなぜ「安定ソート」なのですか?
- A
マージ時に
left[i] <= right[j]と書くことで、等しい値のときは左側(元の順序で前にある方)を先に取り出すからです。
この1つの比較条件が、元の順序を保つことを保証しています。
- Q「再帰」という言葉が出てきましたが、理解しないと実装できませんか?
- A
仕組みを完全に理解しなくても実装できます。
「1要素になるまで半分に分け続け、合体しながら戻ってくる」という動作のイメージをつかんでおけば、コードのパターンは覚えられます。再帰の仕組みが気になった方は、別記事で詳しく解説しています。
- Qマージソートとクイックソートはどちらを使えばいいですか?
- A
一般的にはPythonの
sorted()や言語組み込みのソートを使えばどちらも不要です。
自前実装が必要な場面では、「最悪ケースの速度保証が必要」「安定ソートが必要」ならマージソート、「メモリを節約したい」「平均速度を最大化したい」ならクイックソートを選んでください。
- Qマージソートは並列処理と相性がいいと聞きましたが、本当ですか?
- A
本当です。「左半分を整列」と「右半分を整列」は互いに独立した処理なので、複数のCPUコアや複数のマシンで同時に処理できます。
MapReduceなどの大規模分散処理フレームワークの考え方とも共通しています。
- Q空間計算量O(n)の追加メモリとは具体的にどのくらいですか?
- A
n件のデータをマージソートするとき、マージ時に最大n件分の一時配列が必要になります。
1件が1バイトなら100万件で約1MB追加で必要です。現代の環境では通常問題になりませんが、組み込みシステムなどメモリが極端に制限される環境では考慮が必要です。
まとめ
- マージソートは書類を1枚になるまで分け、比べながら合体させるアルゴリズム
- 計算量は常にO(n log n)。最悪ケースがなく、どんなデータでも安定して速い
- 合体時に追加のメモリO(n)が必要なのが唯一の弱点
- 安定ソートなので元の順序が保たれる。同じ値の順序が重要な処理に向いている
- 「分けて整列して合体」という発想はデータベースの外部ソートや分散処理にも使われている現役の考え方
「1人で100枚を並べるより、50枚ずつ分担して最後にくっつける方が速い」——この直感は正しい。そしてその直感を突き詰めると、1枚になるまで分け続けるマージソートに辿り着く。単純なアイデアが、巨大なデータを処理する現代のシステムの根っこにある。
関連記事
「分割して速くする」という同じ発想のクイックソートと比較したい方はこちら。
→ クイックソートとデカルトの分割統治
マージソートが内部で使う「再帰」の仕組みを理解したい方はこちら。
→ 再帰とは?入れ子の箱で理解するプログラミングの魔法
“`

