
「ノーコードだから簡単」は半分正解で、半分は罠だ。
情シスとして社内AIの導入支援を10件以上こなしてきた経験から言う。Difyで失敗するチームは大抵、「PDFを放り込めばAIが全部やってくれる」という幻想を持ったまま始めている。RAGの精度を左右するのはモデルの賢さより「検索の設計」だ。設定の急所を押さえれば、ノーコードで実用レベルの社内AIが作れる。
本記事では、実測データに基づいたDify構築の失敗しないルールを公開する。
この記事でわかること
- DifyのRAG精度を決める3つのツマミ(チャンクサイズ・Top-k・データ構造)
- PDF直接投入 vs Markdown整形の実測精度比較(62% vs 84%)
- 「分かりません」連発・Token Limitなど現場あるあるエラー5選と対処法
結論:Difyの成否は「設計」で9割決まる
📌 要点:Difyは2026年現在もっとも合理的なRAG開発プラットフォーム。ただし「雑に触ればただの置物」になる。PDFの丸投げ・デフォルト設定放置・閾値ミスが失敗の三大原因。
Difyは、ノーコードでRAG(検索拡張生成)を組み上げられる、2026年現在もっとも合理的な開発プラットフォームだ。
だが、現場でよく見る「動くだけで使い物にならないAI」には共通点がある。
- 丸投げの罠:PDFを未加工で放り込み、誤回答を連発させる
- 設定不足:Top-k(検索件数)やチャンクサイズをデフォルトのまま放置
- 「分かりません」の多発:スコア閾値の設定ミスで、知識があるのに回答を拒否
「正しく組めば最強の武器、雑に触ればただの置物」。 これがDify運用のリアルだ。
Difyとは何か?他ツールとの決定的な違い
📌 要点:Difyの本質は「複数のLLMや知識ベースを束ねるオーケストラ指揮者」。非エンジニアでも実戦投入できる点でLangChainより圧倒的に導入が速い。
DifyはGPT・Claude・Gemini・ローカルLLMなど複数のモデルを束ねて使える「LLMオーケストラ指揮者」だ。2026年3月現在の連携モデルは以下の通り。
- OpenAI系:GPT-4o / GPT-5系
- Anthropic:Claude Sonnet 4.6 / Opus 4.6
- Google:Gemini 2.5 Pro
- Local LLM:Ollama / Llama 3.3(社内秘匿データ用)
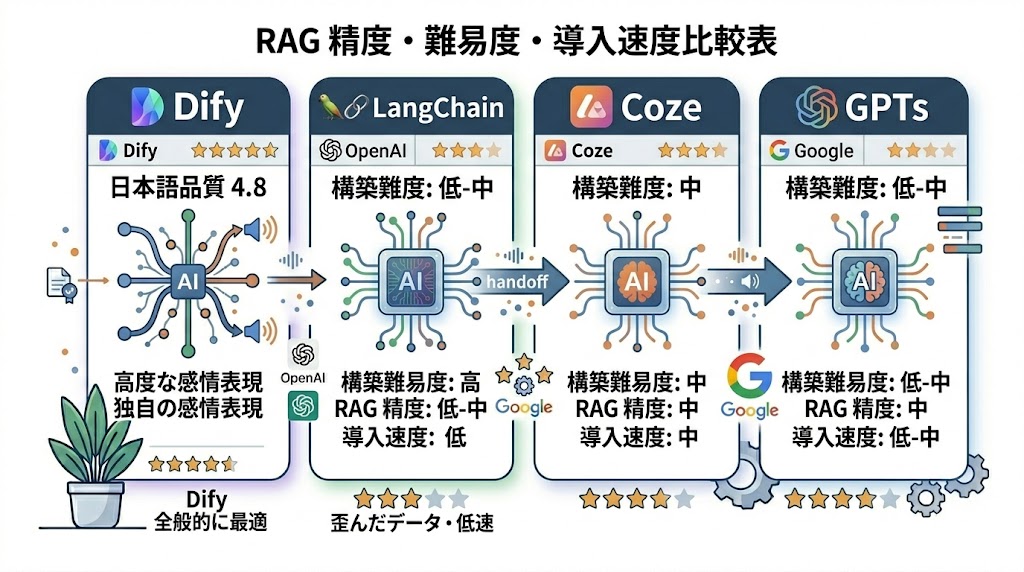
競合ツールとの実務目線での比較はこうなる。
| ツール | 難易度 | RAG精度 | 実務への導入速度 | 備考 |
|---|---|---|---|---|
| Dify | 低 | ◎ | 最速 | 非エンジニアでも実戦投入可能 |
| LangChain | 高 | ◎ | 遅 | 自由度は高いが工数も膨大 |
| Coze | 中 | ○ | 中 | BtoCやSNS連携に強み |
| GPTs | 低 | △ | 速 | 知識量が増えると精度が露呈 |
RAGの仕組み(ブラックボックスのまま触らない)
📌 要点:RAGの精度はモデルの賢さより「検索精度」で決まる。いじるべきツマミは「チャンクサイズ」「Top-k」「データ構造」の3つだけ。
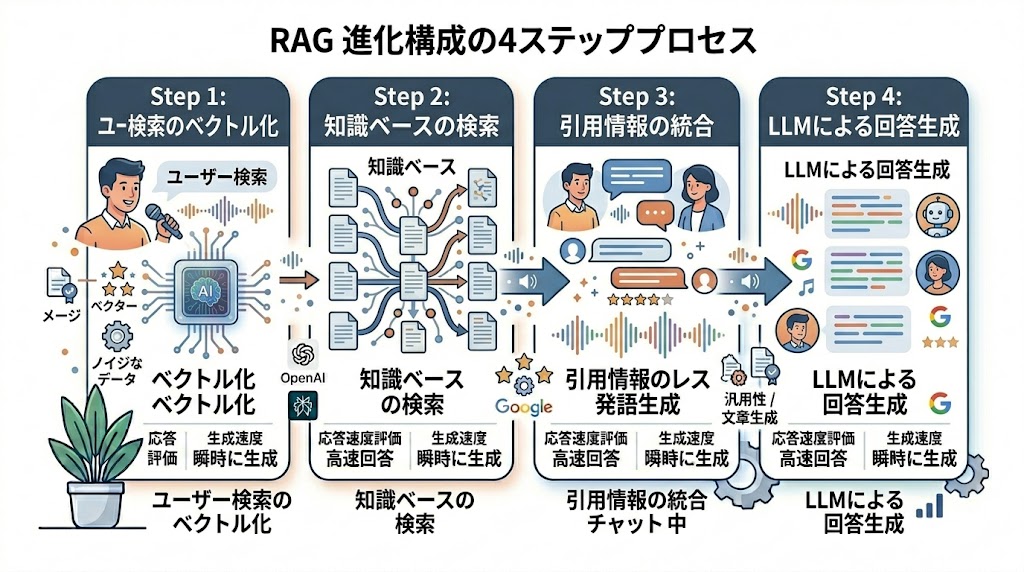
RAGの動作を理解しておかないと、設定ミスの原因がわからない。仕組みはシンプルだ。
- ベクトル化:ユーザーの問いを数値に変換
- 検索:知識ベース(DB)から「似ている情報」を釣り上げる
- 結合:釣り上げた情報をプロンプトに合流させる
- 生成:合流した情報を根拠にLLMが回答
ここでいじるべきツマミは3つ。「チャンクサイズ」「Top-k」「データ構造」。この3点だけで結果は劇変する。
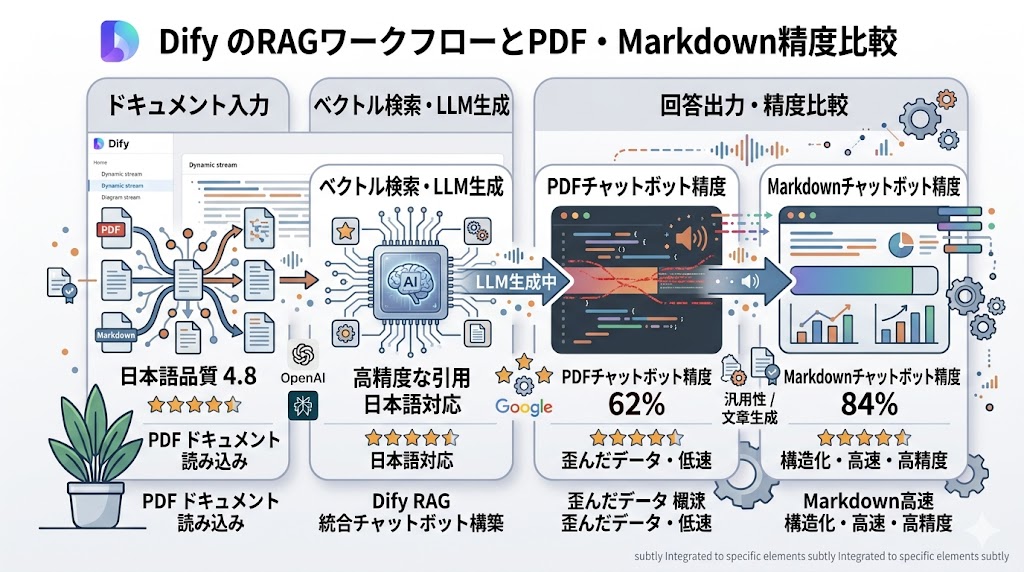
【実測】PDF vs Markdown 精度比較
📌 要点:「PDFをそのまま入れればいい」は幻想。同一内容の社内FAQ5,000文字でPDF直接投入(62%)とMarkdown整形(84%)を実測比較。Markdown化でRAG精度が約20%上がる。
「PDFをそのまま入れればいい」というのは幻想だ。実測データがそれを証明している。
検証条件:
- 内容:社内FAQ 5,000文字
- 試行:同一質問への20回連続テスト
| データ形式 | 正答率 | 平均応答時間 | 現場の感触 |
|---|---|---|---|
| PDF直接投入 | 62% | 5.2秒 | 表や箇条書きの認識ミスが目立つ |
| Markdown整形 | 84% | 4.1秒 | 構造が明確で、回答のキレが良い |
結論:PDFは一度Markdownへ変換して掃除する。このひと手間で精度は20%以上跳ね上がる。
社内FAQ導入時にこのデータを上司に見せたとき、「それだけ変わるなら整形工数を予算に入れよう」という判断が即日出た。数字で示せると意思決定が早い。
失敗を避けるための「最小構成」3ステップ
📌 要点:最小構成は「素のLLMで疎通確認→1000文字でRAGの癖を掴む→段階的に実戦仕様へ拡張」の3ステップ。いきなり大量データを入れないことが最大のコツ。
Step 1:まずは「素のLLM」で疎通確認
APIエラーで時間を溶かしてはいけない。特にDocker環境(Self-host)でハマる人が多い。
- Ollama等のローカル接続なら
localhostではなくhost.docker.internalを指定
Step 2:1000文字のテキストで「RAGの癖」を掴む
いきなり大量の資料を入れないこと。
- チャンク:500〜800文字(意味の塊を維持)
- Top-k:5〜8(参照数を増やして漏れを防ぐ)
- スコア閾値:0.3〜0.4(最初は緩めに設定)
Step 3:段階的に「実戦仕様」へ拡張
- オーバーラップ:10〜15%(文脈の断絶を防ぐ)
- 表データの処理:Markdownの表形式に書き換えるのが一番確実
現場で遭遇する「あるあるエラー」5選
📌 要点:DifyのRAGで詰まるポイントは5パターンに集約できる。「分かりません」頻発・Token Limit・PDF誤読・無限ループ・Ollama接続エラー。それぞれ対処法が決まっている。
① 「分かりません」と回答を拒否される
→ 検索スコアの閾値が高すぎるか、Top-kが足りていない。閾値を0.3〜0.4に下げて再テスト。
② Token Limit(文字数オーバー)
→ チャンクが大きすぎる。情報を細かく刻んで「必要な分だけ」渡す。
③ PDFの読み飛ばし・誤読
→ レイアウト崩れが原因。テキストベースでの再登録を推奨。
④ ワークフローが帰ってこない
→ Iteration(繰り返し)の無限ループ。最大回数の設定は必須。
⑤ Ollamaが見つからない
→ ポート開放(11434)と環境変数の設定ミス。host.docker.internal:11434 を確認。
法人利用とセキュリティの境界線
📌 要点:クラウド版は手軽だがログが残る。機密情報を扱う法人はセルフホスト+ローカルLLMの構成が標準解。情シス部門との連携でAPIホワイトリスト化まで行うのが安全。
情シスとして最も聞かれる質問が「Difyにデータを入れても大丈夫か」だ。答えは構成次第だ。
- クラウド版:手軽だがログが残る。非公開情報には注意
- セルフホスト:自社VPC内に構築。データが外に出ない安心感
- API制御:通信先のホワイトリスト化など、情シス部門との連携が必須
個人情報や機密資料を扱うなら、「Self-host + ローカルLLM」 の構成が標準解だ。医療・金融・公共機関での導入案件では、この構成以外を選択肢に入れることすら難しい。
向いている人/向いていない人
📌 要点:Difyは「社内FAQを爆速で作りたい非エンジニア」に最適。「資料を丸投げすれば全部やってくれる」と思っている人には向かない。地味なデータ整形を厭わない人が成果を出す。
向いている人
- 社内FAQやマニュアル検索を爆速で作りたい
- プログラムは書けないが、AIの「中身」を細かく調整したい
- PoC(概念検証)から本番導入までを最短で駆け抜けたい
向いていない人
- 「資料を丸投げすれば、あとはAIが全部やってくれる」という魔法を信じている人
- 地味な「データ整形(クリーニング)」を面倒に感じる人
今すぐ動くための「15分アクション」
📌 要点:1000文字の社内規定を用意→素のLLMで疎通確認→Top-k=5でナレッジを組んでテスト。この15分で「雰囲気」から「実戦」に変わる。
- 1000文字の社内規定を用意する
- Difyで素のLLMと会話ができるか確認する
- Top-k=5でナレッジを組み、自分の問いに答えられるかテストする
この15分で、組織のAI活用は「雰囲気」から「実戦」に変わる。
FAQ
Q. Difyはクラウドとセルフホストどちらがおすすめ?
まず試すならクラウド版(dify.ai)の無料プランで十分。
機密情報を扱う業務や本番運用を見据えるなら、Dockerを使ったセルフホスト版に移行する。セルフホスト版はオープンソースのため実質無料で運用できる。
Q. RAGに向いている資料の形式は?
Markdownが最もRAG精度が高くなる。
PDFはレイアウトが崩れるため一度Markdownに変換してから登録する。WordやExcelも同様にMarkdown化することを推奨。テキストベースの構造が明確なファイルほど精度が上がる。
Q. チャンクサイズはどう決めればいい?
最初は500〜800文字を推奨。
FAQ形式の資料なら1問1答で1チャンクに揃えると精度が安定する。チャンクが大きすぎるとToken Limitの原因になり、小さすぎると文脈が切れて誤回答が増える。
Q. GPTsと何が違うの?
GPTsは手軽だが知識量が増えると精度が落ちやすい。
DifyはTop-k・チャンクサイズ・スコア閾値などを細かく制御できるため、大量の社内資料を扱う用途に向いている。また複数のLLMを切り替えられる点もGPTsにはない強みだ。
Q. 社内FAQの構築にかかる期間は?
シンプルな社内FAQ(資料10〜20件)なら1〜2日で動くものが作れる。
本番品質(精度80%以上・エラーハンドリング込み)まで仕上げるには1〜2週間を見ておくとよい。
まとめ
- Difyは2026年現在、非エンジニアがRAGチャットボットを実戦投入できる最も合理的なプラットフォーム
- PDF直接投入は禁物:Markdownに整形するだけで精度が62%→84%に向上(実測)
- 3つのツマミ(チャンクサイズ500〜800字・Top-k 5〜8・スコア閾値0.3〜0.4)を押さえれば「分かりません」連発は防げる
- 法人利用は「Self-host + ローカルLLM」が機密情報を扱う場合の標準解
- 15分アクション:1000文字の社内規定→疎通確認→Top-k=5でテスト。これだけで今日から実戦に入れる
Difyは魔法のツールではない。だが「構造を理解し、段階的に積み上げ、データを整える」という王道を歩めば、ノーコードで実用レベルの社内AIを構築できる唯一の近道だ。

