
私たちが本の巻末で当たり前のように使っている「索引」。そして紙の隅に振られた「ページ番号」。
実は、この便利な仕組みが誕生するまでに、人類は紀元前から13世紀まで、およそ2000年もの時間を費やした。
「そんなの、最初から番号を振ればよかっただけじゃないか」と思うかもしれない。しかし、そこには当時の人々にとってある種「サイコパス的」とも言える発想の飛躍が必要だったのだ。
これはGoogle検索が登場する1000年以上前に始まった「検索エンジンの先祖」の物語だ。情シスとしてデータベース設計に長年関わってきた視点から言えば、索引(インデックス)という概念がなければ、現代のデータベースも検索エンジンも存在しない。その起源がいつ、どのような必要性から生まれたのかを知ることは、情報技術の本質を理解する近道になる。
この記事でわかること:
- 1200年代以前、なぜ人類に「検索」という概念が一切存在しなかったのか
- 「蜂の鳴くような読書」を捨てさせた切実なニーズとは何だったか
- ページ数がなぜ「サイコパス的」と言われる発明なのか
- アルファベット順という「意味から形式への移行」という衝撃
- 現代のデータベースのインデックスとの繋がり
1. 魂を刻み込む「蜂の鳴くような読書」と、即答への切実なニーズ
📌 要点:13世紀より前、本は「高価な写本」であり、読書は一言一句を暗記する神聖な行為だった。特定の箇所を素早く検索するニーズ自体が存在しなかった。1230年頃、托鉢修道会が民衆の相談に即答する必要性が生じた瞬間に「外付けの索引」が誕生した。
13世紀より前の世界において、読書は今とは全く異なる神聖で身体的な行為だった。
当時、本は羊の皮をなめして作られた一点ものの「写本」で、家が一軒建つほど高価な貴重品だった。本を読むことのできる限られた層——修道士たちは、聖書の一言一句を疎かにせず、小さな声で音読しながらその内容を自らの頭と魂に叩き込んでいた。
この様子は「蜂の鳴くような読書」と形容される。彼らにとって本は「必要な情報を検索するツール」ではなく、一生をかけて向き合う「対話の相手」だった。最初から最後まで順番に読み、すべてを記憶することが美徳とされていた時代。「特定の箇所を効率よく探したい」などという軽薄なニーズが入り込む余地はなかった。
転機は1230年頃:
ドミニコ会やフランシスコ会といった新しい修道会が登場し、都市へ出て民衆への積極的な布教活動を始めた。すると街の人々から「どうすれば私は救われますか?」「苦しいとき、聖書のどこに答えがありますか?」といった切実な人生相談が次々と寄せられるようになった。
「迷える小羊の質問に答えなきゃいけない」という特殊なニーズが発生した瞬間だった。どれほど信心深い修道士でも、膨大な聖書のすべてを完璧に暗記し即答することには限界がある。彼らには自分の記憶力を補完する「外付けの索引」が、生き残るための武器としてどうしても必要になったのだ。
2. 「意味」への忠誠を捨てた天才たち。ページ数がもたらした残酷なまでの効率化
📌 要点:ページ数はテキストの内容に対して「容赦ないまでに無関心」な発明だ。文の途中でページが終わることも厭わず、忠誠を誓う相手は「ストーリー」でも「議論」でもなく「本という物質」だった。これが当時の人々には「サイコパス的」に見えた。

索引を機能させるためには、情報の「住所」を特定する仕組みが必要だ。そこで登場したのが「ページ数」という概念だが、この発想は当時の常識からすればあまりに非人間的な飛躍を含んでいた。
ページ数以前の情報管理:
情報は「第1章」や「創世記」といった「内容の区切り」で管理されていた。これは人間にとって意味のある、思考の流れを尊重した分け方だ。
ページ数という革命的な発明:
ページ数というシステムは、テキストの内容に対して「容赦ないまでに無関心」だ。
「思考の流れを尊重しないばかりか、容赦ないまでに無関心で、文、更には語までもや もすると途中で切ってしまう。そのロケーターが忠誠を誓う相手は、ストーリーでも議論の内容でもなく、本という物質なのだ」
文の途中でページが終わるという事態は、内容を神聖視する人々からすれば言葉の死を意味した。しかし1230年頃にこの仕組みを思いついたヒューやグロステストといった天才たちは、あえて内容への執着を捨て、「本という物理的な物体」としての座標を優先する決断を下した。
物理技術の進化との相乗効果:
パピルスの「巻物」は、特定の箇所を開くには最初から全部巻き直す必要があった。しかし中世に普及した「冊子(コーデックス)」が、ページをパラパラとめくるというランダムアクセスを物理的に可能にした。思想とテクノロジーが重なった瞬間、人類は2000年の停滞を脱し、情報を「物理的な座標」で支配する術を手に入れた。
文の途中でページが終わることに何の違和感も覚えない私たちは、もう既に当時の人々から見れば十分サイコパスなのかもしれない。
3. アルファベット順の衝撃:意味から綴りへの移行という狂気
📌 要点:かつてリストは社会的序列や意味の重要度で並べるのが普通だった。アルファベット順を持ち込むことは、言葉が持つ神聖な「意味」を殺し、単なる「綴り」という無機質な記号として処理することを意味した。アレクサンドリア図書館の図書館員たちがこの「形式への移行」を行った。
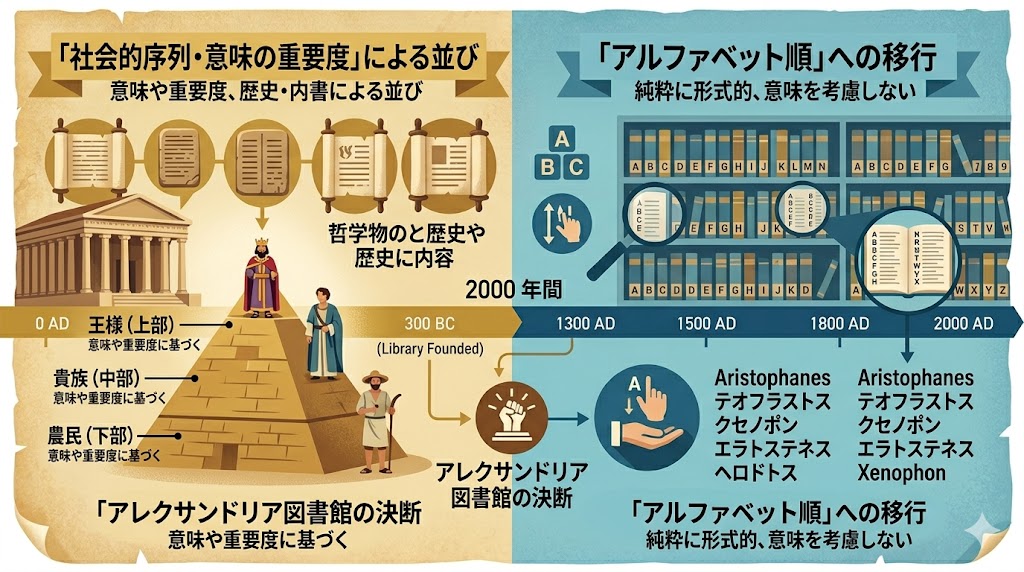
索引を支えるもう一つの柱が「アルファベット順(ソート)」だ。現代の私たちにとって辞書がABC順であることは当然だが、かつてはリストを作る際は「王様が一番上、農民が下」といった社会的序列や、意味の重要度で並べるのが普通だった。
アルファベット順を持ち込むということは、その言葉が持つ神聖な「意味」を一旦殺し、単なる「綴り(スペル)」という無機質な記号として処理することを意味する。
「中身から形式へ、意味から綴りへと移行するのだ」
この「意味を捨てる」という決断が本格的に始まったのは、古代のアレクサンドリア図書館だと言われている。数十万巻に及ぶ膨大なパピルスを整理するためには、もはや「神聖な順序」や「ジャンル分け」では限界だった。そこで図書館員たちは、人間的な分類を諦め、機械的にアルファベット順で並べるという「形式への移行」を選択した。
今、私たちが辞書を引いて一瞬で目的の言葉にたどり着けるのは、遠い昔に言葉の魂を抜き取り、記号として冷徹に扱い始めた人々の決断のおかげだ。
「タイパ批判」との構造的な一致:
この効率化は「読書の崩壊」でもあった。前後関係を完全に無視し、必要なキーワードだけを摘み取るスタイルは、当時の保守的な学者からは「深い理解を損なう浅はかな読み方」と批判された。現代の「タイパ(タイムパフォーマンス)至上主義」や「切り抜き動画」への批判と、驚くほど構造が似ている。効率を手に入れるとき、人類は常に何か大切なものを差し出してきた。
4. 現代のデータベースのインデックスへの繋がり
📌 要点:13世紀の「書籍の索引」と現代の「データベースのインデックス」は同じ思想の異なる実装だ。「意味よりも検索性を優先する」という冷徹な形式化が、情報の海を制御可能にした。
情シスとしてデータベースのパフォーマンスチューニングを担当するとき、最初に確認するのがインデックスの設計だ。
MySQLで「WHERE user_id = 12345」というクエリが遅い場合、user_id にインデックスを貼るだけで劇的に速くなる。これは「user_idというページ番号を振る」ことで、全件走査(O(N))をO(log N)に落とす操作だ。
13世紀の修道士たちが「この節の内容が聖書の37ページに書いてある」と索引を作ったのと、本質的に同じことをしている。「情報の住所(座標)を付ける」という発想が、書籍のページ数からデータベースのインデックスまで一貫して流れている。
FAQ:よくある質問
- Q索引を最初に「発明した」のは誰ですか?
- A
特定の一人ではない。
13世紀のドミニコ会・フランシスコ会の修道士たちによって徐々に発展したとされている。聖書の用語索引(コンコーダンス)の最初の体系的な試みは1230年頃、パリのドミニコ会士たちによるものとされる。
- Q日本語の索引はアルファベット順とどう違いますか?
- A
五十音順がアルファベット順に相当する。
ただし日本語は漢字という「読みが複数ある文字」を持つため、索引の作成は欧文より複雑だ。同じ漢字でも「人名には特殊な読み方がある」問題が現代のデータベース設計にも引き継がれている。
- Q「インデックス」という言葉はなぜ索引という意味になったのですか?
- A
ラテン語のindex(指標・指示するもの)から来ており、「指で指し示す」という意味だ。
書籍の索引もデータベースのインデックスも「特定の情報を素早く指し示す仕組み」という本質は同じで、同じ語源を持つのは必然だ。
- Q電子書籍になった今、索引の意義はありますか?
- A
索引の意義は変わらず重要なままだ。
電子書籍では全文検索ができるが、それは毎回O(N)の線形探索に相当する。一方、適切に構造化された索引はO(log N)の効率を持つ。膨大なコーパスを扱う検索エンジンが「転置インデックス」を使うのも同じ理由だ。
- Qアレクサンドリア図書館はいつ、なぜ失われたのですか?
- A
紀元前3世紀頃に設立され、複数の火災や略奪を経て4〜7世紀頃に実質的に消滅したとされるが、正確な経緯は諸説ある。数十万巻の写本を収蔵していたとされ、その消滅は古代知識の大きな損失だった。
ただし「一度の大火で全滅した」という俗説は正確ではなく、長い年月をかけて徐々に衰退したと考えられている。
まとめ
索引は「意味を捨て、形式を選ぶ」という人類の大きな決断から生まれた。
- 索引は、13世紀の修道士が民衆の相談に即答するための「実利的な武器」として誕生した
- ページ数はテキストの意味や文脈を無視し、物理的な紙を優先する「サイコパス的な合理性」から生まれた
- アルファベット順のソートは、膨大な情報を管理するために「意味への忠誠」を捨てて「形式」を取った情報革命の産物だ
- 現代のデータベースのインデックスは、13世紀の書籍索引と同じ思想の異なる実装だ
「意味よりも検索性を優先する」という冷徹な形式化が、情報の海を制御可能にした。次にデータベースにインデックスを貼るとき、13世紀の修道士たちの「サイコパス的な決断」に思いを馳せてほしい。
関連記事:Notionの破綻を防ぐ「関係モデル」の極意
関連記事:二分探索木(BST)とは?計算量O(log n)の仕組みを図解でわかりやすく解説
“`

