
「彁」や「暃」といった、意味も読みもない「幽霊文字」。
もしこれらをPCやスマホで入力しても、システムが壊れることはない。しかし相手には「解読不能な虚無」が届くだけだ。
なぜ日本の国家規格に、こんな”幽霊”が紛れ込んでしまったのか。その正体は、1978年制定の「JIS C 6226」(通称:78JIS)策定時に起きた「ハサミでの切り貼りミス」や「原稿の汚れ」という、あまりに人間臭い、史上最大の誤植だった。
文字コードの問題を長年扱ってきた。「彁という文字が入力できない」「このデータは何ですか?」という問い合わせに対し、「幽霊文字です。誤植です。使わないでください」と説明するたびに、デジタルの世界の奥深さを実感する。
この記事でわかること:
- 幽霊文字を書くと現代環境で何が起きるか(技術的な結論)
- なぜ「存在しない漢字」が国家規格に紛れ込んだのか
- 最後まで出典不明だった12文字の一覧
- 「幽霊」の汚名を晴らした名誉挽回の例外ケース
- なぜ消去できないのか(互換性という呪い)
1. 幽霊文字を「書くとどうなる?」現代の結論
📌 要点:現代環境では実害はほぼゼロだが、意味も読みも伝わらない「虚無」が届く。古いシステムを経由すると文字化けのリスクあり。現在のAIは「幽霊文字である」と正確に認識できる。
① 表示はされるが「虚無」が届く
現代の文字コードの世界標準「Unicode」には、JIS規格との互換性を保つために幽霊文字もすべて収録されている。最新OSであれば「漢字の形」として正しく表示される。しかし読みも意味もないため、送信相手には「意図不明の不気味な漢字」が届くだけだ。
② 古いシステムでは文字化けのリスク
Shift_JIS形式のみを想定したデータベースや古いシステムを経由すると、高い確率で文字化けを起こす。システムが壊れるわけではなく「想定外のコード」として拒絶されるだけだが、データが欠損する可能性はある。
③ 現在の主要プラットフォームでの実入力結果
- SNS(X等):入力・投稿は可能。ただし読みが設定されていないため「手書き入力」や「コードポイント入力」以外では出現させることが困難
- Google検索:一文字検索でのヒット件数は実質0件(解説サイトを除く)
- AI(2026年最新LLM):「彁の意味を教えて」と問うと「JIS規格の誤記による幽霊文字です」と正確に回答される
2. なぜ生まれた?1978年JIS規格が犯した「12文字の怪」
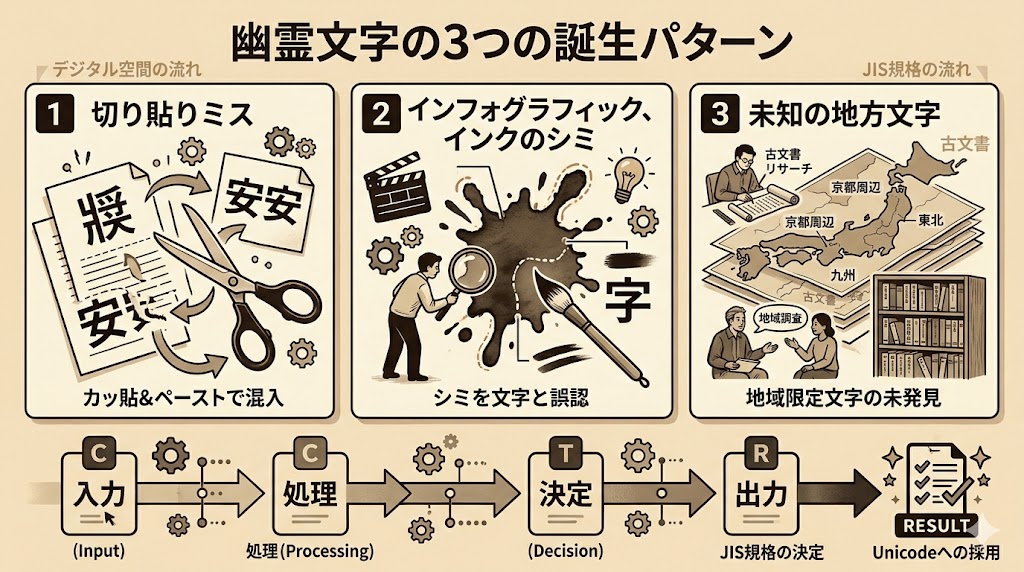
📌 要点:幽霊文字のほとんどは「切り貼りミス」「原稿の汚れ」「出典不明の地方文字」の3パターンで生まれた。1997年の悉皆調査で多くの出典が判明したが、最終的に12文字は今も出典不明のまま残っている。
パターン1:「紙の継ぎ目」が漢字になった
幽霊文字の多くは、資料の切り貼りの際に生まれた。「彁」という文字は「強」あるいは「謌」という文字が、ハサミで切られ別の文字のパーツと偶然くっついたことで生まれた「合成モンスター」である可能性が濃厚だ。
パターン2:汚れが「点」として記憶された
原稿についたゴミやインクの跳ねが、点や線として写し取られ新種の漢字として登録されたケースもある。
パターン3:調査から逃げ切った「12文字」
1997年、国立国語研究所の笹原宏之氏らを中心に行われた「JIS漢字の典拠に関する悉皆調査」により、多くの幽霊文字の「元ネタ」が判明した。しかし最後まで出典が不明とされた文字が12文字残った。
正体不明の12文字:
彁・暃・椦・槞・蟐・袮・閠・駲・墸・壥・妛・挬(これらは戸籍にも地名にも存在しない、純粋な「幽霊」だ)
3. 【例外】実は誤植ではなかった?「名誉挽回」を果たした文字たち
📌 要点:長年「幽霊」の汚名を着せられながら、近年の精緻な調査で「実在の証拠」が見つかり正当な漢字として再評価されたケースが複数ある。デジタルが記録を残したことで、かえって埋もれた文字が救われた事例だ。
「妛(し)」:行政ミスが生んだ悲劇のヒロイン
最も有名な逆転劇が「妛」だ。長らく実在しない字とされてきたが、滋賀県にある地名「阿安ヶ谷(ああがや)」の「𡚴(あ)」という字が元ネタであることが判明した。行政資料のコピーを繰り返すうちに下部が欠け、偶然にも「女」に見えてしまったもの。「幽霊」ではなく「負傷した実在の文字」だったのだ。
「蟐(じょう)」:古文書に眠っていた生きた証
かつては写し間違いと目されていたが、その後の調査により江戸時代の本草学(博物学)の文献で、特定の昆虫を指す文字として使用されていた形跡が発見された。
「槞(ろう)」:地方でひっそり生き延びた「国字」
当初は出典不明とされていたが、一部の地方の古い地名や特定の家系で使用されている実態が報告された。中央には知られていなかった「地方独自の漢字(国字)」だったと言える。
これらのケースは、デジタルが文字を記録し続けたことで、かえって消えかけていた文化が掘り起こされた例でもある。
4. 消去できない「互換性」という名の呪い
📌 要点:一度JIS規格として公開されUnicodeに組み込まれると、削除すれば過去のデータが全世界でエラーを起こすため事実上消去不能。1978年の不注意が2026年の今も、そして未来も全デバイスのストレージを占有し続ける。
「間違いなら消せばいい」と思うかもしれないが、デジタル世界においてそれは不可能だ。
一度決めたら「死んでも直せない」
一度JIS規格として公開され、Unicode等の国際標準に組み込まれてしまうと、その文字を消すことはできない。もし削除すれば、過去のデータがすべてシステムエラーを引き起こすからだ。
例えば、誰かの名前に幽霊文字が使われている戸籍データが仮に存在した場合(行政ミスが元の文字「妛」のように)、その文字コードを削除すればその人の名前がシステム上から消滅してしまう。
技術的負債の象徴
幽霊文字は、私たちエンジニアが負い続ける「負債」だ。1978年の不注意が、2026年の今も、そして未来も世界中のデバイスのストレージを占有し続ける。デジタルは一度記憶した「嘘」を修正するほど寛容ではない。
FAQ:よくある質問
Q. 幽霊文字は現在も新しく生まれる可能性がありますか?
Unicodeへの新規追加プロセスは現在非常に厳格で、出典の証拠が求められる。
1978年のような「作業ミスが規格になる」事態が起きる可能性は極めて低い。ただし歴史的に使われてきた地方文字や特殊な業界用字については、調査が不十分なまま収録されているケースがゼロではない。
Q. 幽霊文字は読み方はあるのですか?
日本語入力ではほぼ設定されていないため、通常の読み方入力では出現させられない。
Unicodeのコードポイントを直接入力する方法(例:Wordで「5F41」と入力してAlt+Xを押す)で入力できるが、読みは存在しないか不確かだ。
Q. 幽霊文字に似た問題は他の言語にもありますか?
存在している。
中国語(CJK統合漢字)にも類似した問題があり、Unicodeへの収録過程で複数の出典資料を照合せずに採用したため、実在が疑わしい文字が含まれているケースが報告されている。日本語特有の問題ではない。
Q. 「彁」という文字はなぜ有名なのですか?
最もよく知られた幽霊文字の一つで、JIS規格に「カ」という読みが割り当てられているにも関わらず出典が全く不明という典型例だからだ。
「幽霊文字」という概念を広めた研究において最初に取り上げられたことで知名度が高い。
Q. 幽霊文字が名前に使われている人はいますか?
「妛」のように、行政ミスが元の文字がレアな地名に使われていたケースはある。
幽霊文字そのものが人名に使われている確実な例は確認されていないが、JISの異体字や出典不明の文字が戸籍に記録されていたケースは歴史的に存在する。
まとめ
幽霊文字を書いても爆発はしない。しかし入力するたびに、半世紀近く前の「不器用な人間たちの作業ミス」を追体験している。
- 幽霊文字を書いた結果:実害はないが意味も伝わらない「虚無」が届く
- 幽霊文字の正体:写し間違い・切り貼りミス・忘れ去られた地方の記憶
- なぜ残っているのか:Unicodeに組み込まれたデータを削除すると世界中の過去データが破損するから
- 一部の幽霊文字は後の調査で「実在」が判明し、名誉を回復した
完璧を求めるコンピュータの世界に残された、人間らしい愛すべき傷跡。それが幽霊文字の正体だ。
関連記事:文字化けの正体|UTF-8とShift_JISの衝突をバイト列で見る
関連記事:128個の椅子を奪い合った「文字コード闘争史」
“`

