

回転寿司で「サーモンどこだ…」と探した経験はないだろうか。
流れてくる皿を端から1枚ずつチェックしていく。マグロ、違う。玉子、違う。エビ、違う。ハマチ、違う。サーモン、あった!終了。 ——これが線形探索だ。コンピュータが配列の中から値を探すとき、まったく同じことをやっている。
「アルゴリズムって難しそう」と感じているなら、線形探索から入るのが正直一番いい。あなたがすでに日常でやっている「探し方」がそのままコードになっているからだ。
この記事でわかること
- 線形探索の仕組みを回転寿司の比喩で直感的に理解する
- 計算量O(n)が「何が増えると何が増えるか」を正確に把握する
- 二分探索との違いと、線形探索を使うべき場面の判断基準
- PythonとJavaScriptの実装コードと、バグになりやすい落とし穴
回転寿司で理解する線形探索の動作
📌 要点:レーンの皿を先頭から1枚ずつ確認する。目当ての皿が見つかれば即終了、全皿見ても見つからなければ「なし」と返す。前提条件ゼロで動く最もシンプルな探索アルゴリズム。
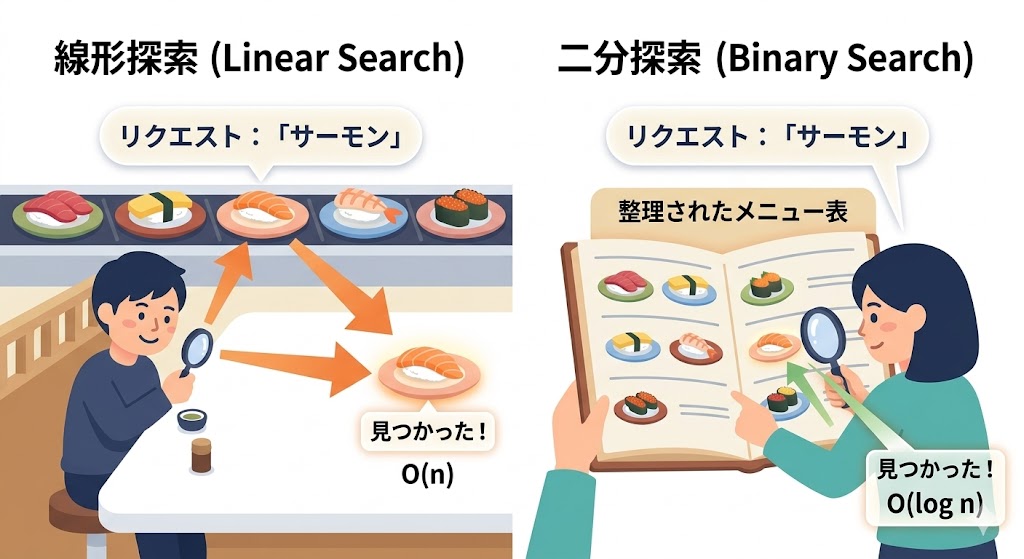
線形探索(Linear Search)とは、配列の先頭から末尾に向かって1要素ずつ順番に比較していく探索アルゴリズムだ。
回転寿司のレーンに10枚の皿が流れているとしよう。
[マグロ, 玉子, エビ, イカ, ハマチ, サーモン, タコ, ウニ, イクラ, カニ]「サーモン」を探す場合、線形探索はこう動く。
| 確認順 | 皿の内容 | 判定 |
|---|---|---|
| 1枚目 | マグロ | ❌ 違う |
| 2枚目 | 玉子 | ❌ 違う |
| 3枚目 | エビ | ❌ 違う |
| 4枚目 | イカ | ❌ 違う |
| 5枚目 | ハマチ | ❌ 違う |
| 6枚目 | サーモン | ✅ 見つかった!即終了 |
6枚確認した時点で終わり。レーンの並び順には関係ない。事前にソートする必要もない。特別な前処理も一切不要。これが線形探索の最大の強みだ。
もし「サーモン」がレーンに存在しなければ、10枚全部確認してから「なし」と返す。最悪の場合は全皿チェックになる。
Pythonで実装すると
def linear_search(arr, target):
for i, value in enumerate(arr):
if value == target:
return i # 見つかったインデックスを返す
return -1 # 全皿確認しても見つからなかった場合
# 実行例
menu = ["マグロ", "玉子", "エビ", "イカ", "ハマチ", "サーモン", "タコ"]
result = linear_search(menu, "サーモン")
print(result) # → 5(インデックス5にある)
result2 = linear_search(menu, "アワビ")
print(result2) # → -1(存在しない)JavaScriptで実装すると
function linearSearch(arr, target) {
for (let i = 0; i < arr.length; i++) {
if (arr[i] === target) return i;
}
return -1;
}
const menu = ["マグロ", "玉子", "エビ", "イカ", "ハマチ", "サーモン", "タコ"];
console.log(linearSearch(menu, "サーモン")); // → 5
console.log(linearSearch(menu, "アワビ")); // → -1ループを1回まわして比較するだけ。これ以上シンプルなアルゴリズムはなかなかない。
O(n)とは何か:皿の枚数が増えると確認回数が増える
📌 要点:O(n)とは「皿が10枚なら最大10回、100枚なら最大100回」という線形比例の関係。データが2倍になれば最悪ケースの処理も2倍になる。nはデータ量そのものを指す。
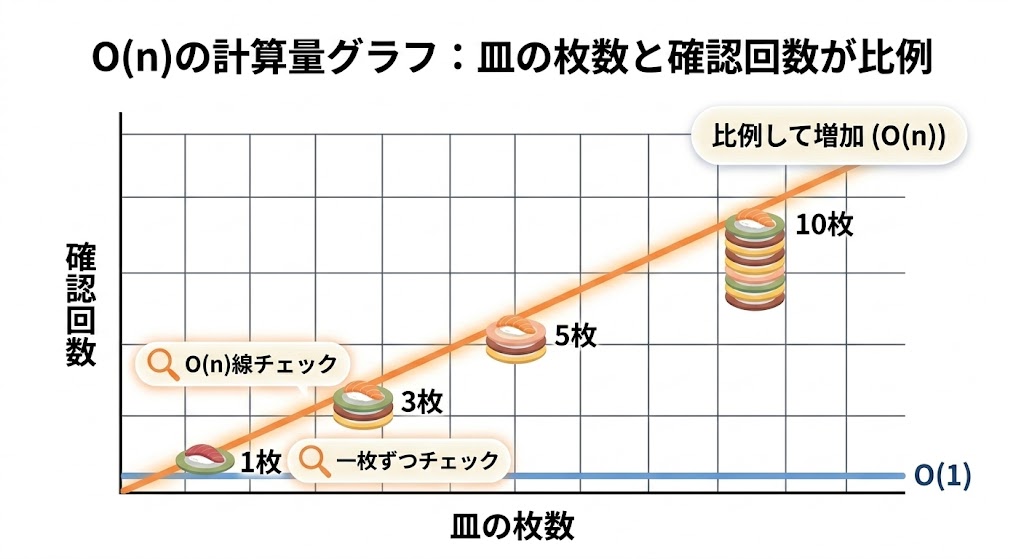
線形探索の計算量は O(n) と書く。nはレーン上の皿の枚数——つまり配列の要素数だ。
| ケース | 確認回数 | 回転寿司に例えると |
|---|---|---|
| 最良ケース O(1) | 1回 | 最初の皿がサーモンだった |
| 平均ケース O(n/2) | n÷2回 | 中間あたりでサーモンが来た |
| 最悪ケース O(n) | n回 | 最後の皿がサーモン、またはそもそも存在しない |
アルゴリズムの評価では最悪ケースで考えるのが基本だ。「どんなに運が悪くても最大何回で終わるか」がわかれば、システムの性能保証に使える。
レーンに100枚あれば最大100回確認、1万枚なら最大1万回。皿が増えた分だけ待ち時間も増える——それがO(n)の本質だ。
二分探索との違い:レーン全確認 vs メニュー表で半分に絞る
📌 要点:二分探索はO(log n)で圧倒的に速いが「ソート済みデータ」が必須条件。線形探索は遅いが条件なしで動く。「データがソートされているか」が使い分けの判断軸になる。
「だったら二分探索のほうが速いんじゃないの?」——その疑問は正しい。
比喩で言えば、二分探索は「あいうえお順に並んだメニュー表」を使う探し方だ。「さ行」に目を向ければサーモンはすぐ見つかる。全ページを見る必要はない。
ただし、メニュー表がきちんと50音順に整列していることが前提だ。
| 比較項目 | 線形探索(レーン全確認) | 二分探索(メニュー表) |
|---|---|---|
| 計算量 | O(n) | O(log n) |
| 前提条件 | なし | ソート済みであること |
| 実装の複雑さ | 非常に簡単 | やや複雑 |
| データ構造 | 何でもOK | ソート済み配列のみ |
| 適したデータ量 | 小〜中規模 | 中〜大規模 |
1万件のソート済みデータに二分探索を使えば最大 log₂(10000) ≈ 14回の比較で見つかる。線形探索の1万回とは天と地の差だ。
ただし、現実の業務ではこの「ソートされている」という前提が崩れていることが多い。
情シス部門で資産管理DBの検索が遅いと相談を受けたことがある。確認してみると、担当者が手動でメンテしていたCSVは購入日順でも名称順でもなく、更新のたびに行が追加されただけのデータだった。二分探索を実装しても正しく動かない。ソートが保証されていないデータには、線形探索のほうが安全で確実だ。
線形探索が実際に使われる場面
📌 要点:「遅いから使わない」は半分間違い。データが少ない・ソートが保証されない・一度しか使わない探索では線形探索が最も合理的な選択。問題の規模に合った手法を選ぶのが本質。
「O(n)は遅い。だから線形探索はダメだ」という判断は、表面だけ見ている。
線形探索が適している場面:
- データが少ない(100件以下):高速化のコストが見合わない。10件のリストに二分探索を実装するのはオーバーエンジニアリングだ
- ソートされていないデータ:ソートのコスト(O(n log n))をかけるより線形探索のほうが速いことがある
- 一度しか探索しない:前処理のコストを回収できない
- 連結リスト:インデックスアクセスができないため二分探索が使えない
- 文字列の部分一致検索:前から順番に比較するのが基本
「問題の規模に対して適切な手法を選ぶ」——これがアルゴリズム選択の本質だ。回転寿司のレーンに3枚しか皿がないなら、メニュー表を開く手間のほうが無駄になる。
実装で踏みやすい落とし穴
📌 要点:線形探索のコードは単純だが「見つからなかった時の戻り値」「複数一致の扱い」「型の不一致」の3点でバグが生まれやすい。仕様を先に固めてから実装する。
シンプルなコードほど、仕様の曖昧さがそのままバグになる。
落とし穴①:見つからなかった場合の戻り値を忘れる
def linear_search_bad(arr, target):
for i, value in enumerate(arr):
if value == target:
return i
# return -1 を忘れると None が返る → 呼び出し元でエラー
def linear_search_good(arr, target):
for i, value in enumerate(arr):
if value == target:
return i
return -1 # ← 必ず明示する落とし穴②:複数一致する場合の仕様が曖昧
「最初の1件だけ返す」か「全件返す」かで実装が変わる。仕様を決めてから書く。
# 全件返す場合
def linear_search_all(arr, target):
return [i for i, value in enumerate(arr) if value == target]落とし穴③:型の不一致
arr = [1, 2, "3", 4, 5]
linear_search(arr, 3) # → -1("3"と3は型が違うため不一致)
linear_search(arr, "3") # → 2(文字列の"3"は一致)型が混在しているデータに対して検索するとき、検索値の型に注意する。
FAQ
- Q線形探索と逐次探索は同じですか?
- A
逐次探索も同じです。
「逐次探索」は日本語での別名で、英語の “Sequential Search” の訳語として使われます。「シーケンシャルサーチ」とも呼ばれますが、すべて同じアルゴリズムです。
- Qソート済み配列に線形探索を使う意味はありますか?
- A
線形探索を使う意味があります。ソート済みであることを利用して「目的の値より大きい要素に達したら打ち切る」最適化(番兵法)が可能です。ただし最悪ケースはO(n)のままなので、大量データには二分探索を使うべきです。
- QPythonの「if x in list」は線形探索ですか?
- A
はい、リストに対しては内部で線形探索を行いO(n)です。
一方、setやdictに対するinはハッシュテーブルを使うためO(1)になります。「何のデータ構造に対してinを使うか」で速さが大きく変わります。
- Q何件までなら線形探索で実用的ですか?
- A
1000件未満なら体感上の差はほぼありません。
ミリ秒以下の処理です。毎秒数千回の検索が発生するような高頻度処理では、1万件を超えたあたりから二分探索やハッシュテーブルへの切り替えを検討してください。
- Q二次元配列にも線形探索は使えますか?
- A
二次元配列にも線形探索が使えます。
ネストしたループで全要素を走査します。ただし計算量はO(n×m)(n行×m列)になります。10行×10列の100要素なら最大100回の比較です。
- Q線形探索は安定探索ですか?
- A
「安定探索」という概念は通常ソートに使う言葉ですが、線形探索は先頭から順番に確認するため、同じ値が複数あるとき「最初に一致したもの」を返します。
この一貫した動作は安定していると言えます。
まとめ
- 線形探索はレーンを先頭から1枚ずつ確認する回転寿司の探し方そのもの
- 計算量はO(n)。皿(データ)が増えた分だけ確認回数も増える
- 前提条件ゼロで使えるのが最大の強み。ソート不要、データ構造を選ばない
- 二分探索より遅いが、小規模データ・ソートが保証されない場面では最も合理的
- 実装時は「見つからなかった場合の戻り値」「複数一致の扱い」「型」の3点を先に決める
サーモンを探して全皿見てしまうのは非効率に見える。でもレーンに3枚しかないなら、それが最速の方法だ。アルゴリズムの選択は「速いか遅いか」だけで決まらない。問題の規模と状況に合わせて選ぶ——その判断力がエンジニアとしての本当の武器になる。
関連記事
アルゴリズムの計算量をもう少し体系的に理解したい方はこちら。
→ アルゴリズムのオーダー記法をマンガで理解する
探索から一歩進んで、「効率よく整列させる」ソートアルゴリズムの世界へ。
→ クイックソートとデカルトの分割統治
“`
