
「きちんと指示したはずなのに、AIが無視した部分がある。」
情シスとして社内のAI活用研修を担当していると、この経験談は必ず出てくる。プロンプトをいくら丁寧に書いても、AIが「見落とす」ポイントがある。これはランダムな誤動作ではなく、生成AIの構造的な特性から来ている。
生成AIは「次の単語を確率的に予測するエンジン」だ。この基本的な仕組みを理解すると、なぜAIが中間の指示を無視するのか、なぜ一度決まった回答方向から外れないのかが見えてくる。
4つの特性を知って対策を取るだけで、プロンプトの精度は大きく変わる。
この記事でわかること
- 生成AIが「次の単語予測」で動く仕組みとプロンプトへの影響
- 指示を無視される「4つの特性」と具体的な対策
- Lost in the Middle現象・回答の方向性固定の実践的な回避策
なぜプロンプトが重要か?「単語予測」の原理
📌 要点:生成AIは文章の「次の単語を確率的に予測」するエンジン。プロンプトはAIが次の単語を選ぶ確率分布を操作する設計図だ。この仕組みを知ることで、なぜ特定の書き方が効くのかが理解できる。
生成AIは魔法の箱ではなく、内部では「次に来る単語の確率が最も高いものを選ぶ」という処理を繰り返している。
文章はトークンという最小単位に分割され、前から後ろへ情報を渡しながら次のトークンが予測される。この仕組みから4つの特性が生まれ、プロンプト設計のポイントが決まる。
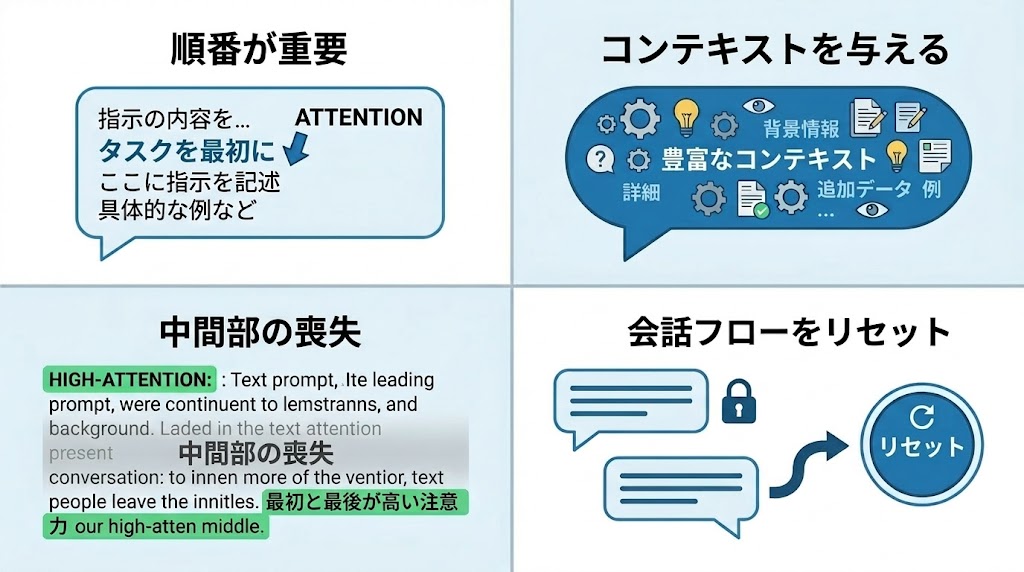
特性①:プロンプトの順番|タスクを先に書く
📌 要点:AIはプロンプトの前半を読んで「どう処理するか」を決定する。タスクの指示を先に書くと、後続の情報をその文脈で読んでくれる。「翻訳してください→文章」より「文章→翻訳してください」の方が精度が落ちる。
AIは先に「何をするか」を知った上で、後続の情報を処理する。
❌ 精度が下がりやすい順番:
[長い文章データ]
上記を日本語に翻訳してください。✅ 精度が上がりやすい順番:
以下の文章を日本語に翻訳してください。
[翻訳する文章]人間でも「この情報を読んでください」と言われた後に「数字を数えながら読んでください」と言われるより、先に「数字を数えながら読んでください」と言われた方が正確に処理できる。AIも同じだ。
対策:タスクの指示を先に書き、データ・文章・情報はその後に渡す。
特性②:コンテキストの重要性|背景情報を充実させる
📌 要点:AIは前の文章を元に次の単語を予測するため、コンテキスト(背景情報)が多いほど精度の高い回答が出る。「メールを作って」より「私は〇〇の営業で、△△さんへの初回メールです。目的は〜」の方が使える出力になる。
AIの回答精度はコンテキストの量と質に比例する。
❌ コンテキストが薄いプロンプト:
メールを作成してください。✅ コンテキストが充実したプロンプト:
私は IT企業の法人営業(5年目)で、初めてアプローチする製造業の担当者へのメールを書きたい。
目的:来月のウェビナーへの招待
相手の課題:DX推進に取り組んでいるが社内リソースが不足していると聞いている
トーン:丁寧だが押しつけがましくない
上記の状況でメールの件名と本文を作成してください。社内研修でこの比較を見せたとき、「コンテキストを書く手間より、使えない出力を書き直す手間の方がずっと大きい」という感想が多く出た。最初の5行の投資が、後工程の修正工数を減らす。
対策:「誰が・誰に・なぜ・どんな状況で」を先に書く。具体的なほど精度が上がる。
特性③:中間部の喪失(Lost in the Middle)|重要情報は最初か最後に
📌 要点:AIは長いプロンプトや会話の「最初と最後」に注意を向け、中間部を無視する傾向がある。「Lost in the Middle」と呼ばれるこの現象は、コンテキストが長いほど顕著になる。重要なルールや制約は必ず最初か最後に配置する。
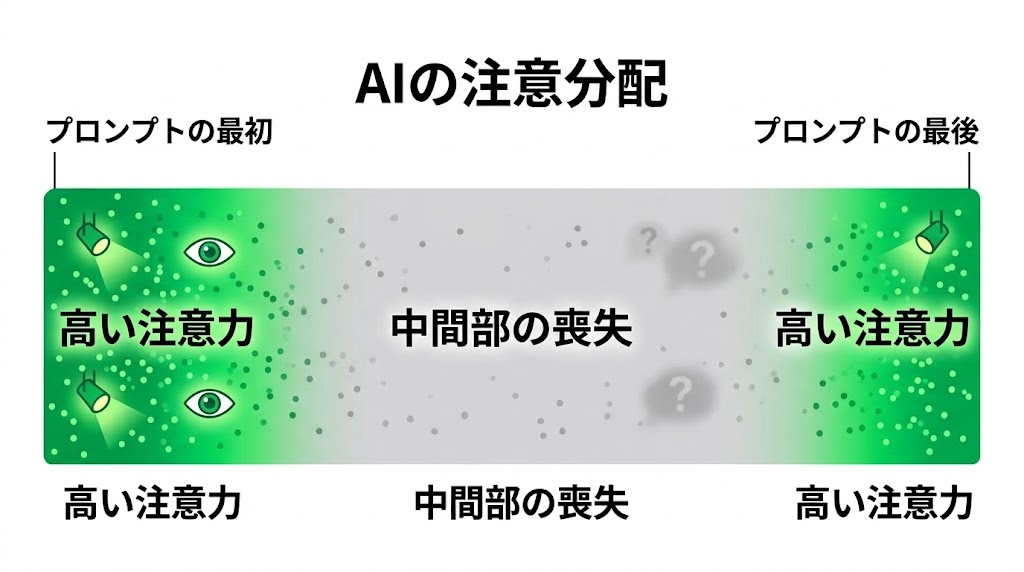
AIは提供された情報の最初と最後に強く注意を向け、中間部の情報を軽視する傾向がある。これを「Lost in the Middle(中間部の喪失)」という。
本を読んだとき「冒頭と結末はよく覚えているが中盤の展開が曖昧」という経験に似ている。AIも構造的に同じ傾向を持つ。
この現象が問題になる場面:
- 長いシステムプロンプトの中間に「〜は絶対に含めないこと」と書いたのに守られない
- 長い会話の途中で設定したルールがいつの間にか無視される
- 大量の資料を渡したとき、中間にある重要情報が回答に反映されない
対策:
① 重要なルール・制約・守ってほしい条件は
プロンプトの「最初」か「最後」に書く
② プロンプトが長くなるなら、
最後に「上記の条件を必ず守ること」とリマインドを追加する
③ 重要情報を中間に書かざるを得ない場合は
冒頭で「特に〜の条件に注意すること」と予告する特性④:回答の方向性固定|引きずられるなら新規チャット
📌 要点:AIは一度決まった回答の方向性から大きく外れることが苦手。「全く違う切り口で」と指示しても最初の前提に引きずられる。軌道修正が難しい場合は「新規チャットを立ち上げる」が最も確実な解決策。
AIは確率的に一貫した内容を生成しようとするため、一度会話の方向性が定まると大幅な軌道修正が難しくなる。
よくある困るケース:
- アイデア出しで最初に「コスト削減案」が出てきた後、「全く違う切り口で」と指示しても、コスト削減の文脈を引きずったアイデアが出続ける
- 文章のトーンを「フォーマルに」と最初に設定した後、途中で「もっとカジュアルに」と言っても中途半端なトーンになる
2つの解決策:
方法①:明示的なリセット指示
これまでの内容は完全にリセットしてください。
ここからは全く異なる前提で考えてください。
前提:[新しい前提を書く]方法②:新規チャットを立ち上げる(最も確実)
正直なところ、大幅な軌道修正が必要なら新規チャットが一番確実だ。「気持ちのリセット」と同じで、前の文脈を完全にゼロにした状態から始める方が出力の質が上がる。
複数のプロジェクト案の比較検討をChatGPTで行ったとき、同じチャットで「案Aの視点で」「案Bの視点で」と切り替えを繰り返したら、どちらの案の良い点も出てこなくなった。新規チャットで案ごとに分けてから、品質が一気に上がった。
4つの特性まとめ早見表
| ①順番 | タスク後置だと処理精度が落ちる | タスク指示→データの順に書く |
| ②コンテキスト | 背景情報が薄いと平均的な回答になる | 誰が・誰に・なぜを先に書く |
| ③中間部の喪失 | 中間の指示が無視される | 重要条件は最初か最後に配置 |
| ④方向性の固定 | 軌道修正が難しい | 新規チャットで仕切り直し |
FAQ
Q. Lost in the Middleは全モデルで起きる?
程度の差はあるが、GPT-4o・Claude・Geminiいずれのモデルでも起きる。
コンテキスト窓が大きいモデル(Gemini 2.5 Pro等)でも完全には解消されていない。重要情報を中間に置かないという設計原則は全モデルで有効だ。
Q. コンテキストはどこまで詳しく書けばいい?
「この情報がなければAIが誤った前提で答えてしまう」というものを全部書く感覚が適切だ。
過剰なコンテキストよりも「必要な情報が欠けている」方が精度への影響が大きい。まず書きすぎて、不要な部分を後で削る方向で調整するといい。
Q. 「これまでの内容を忘れて」という指示は本当に効く?
部分的には効くが完全なリセットは難しい。
会話のコンテキスト(トークン)は物理的に残っているため、AIが完全に「忘れる」わけではない。大幅な方向転換が必要なら新規チャットの方が確実だ。
Q. プロンプトはどのくらいの長さが適切?
「必要な情報が全部入っていて、不要な情報が入っていない長さ」が理想だ。
短すぎるとコンテキスト不足で平均的な回答になる。ただし長すぎるとLost in the Middleのリスクが上がる。1,000〜2,000文字程度を目安に、重要条件を最初・最後に配置するのが現実的なバランスだ。
まとめ
- 特性①(順番):タスク指示を先に書き、データは後に渡す
- 特性②(コンテキスト):「誰が・誰に・なぜ・どんな状況で」を最初に書く。具体的なほど精度が上がる
- 特性③(中間部の喪失):重要なルール・制約は最初か最後に配置。長いプロンプトは最後にリマインドを入れる
- 特性④(方向性の固定):大幅な軌道修正が必要なら新規チャットで仕切り直しが最速
「なぜAIが指示を無視するのか」の原因がわかると、プロンプトの設計が根拠を持ったものになる。次にAIが思った通りに動かないときは、この4つの特性のどれが原因かを確認してみてほしい。

