

分厚い英和辞典で「symphony」を探すとき、あなたはどうするか。
1ページ目から順番にめくっていく人は、まずいない。たいていこうする。真ん中あたりをパッと開く。「M」だった。symphonyは「S」だから後半だな。後半の真ん中を開く。「R」だった。もう少し後ろ。また真ん中を開く…… 数回繰り返せば目的のページに辿り着く。
これが二分探索だ。
線形探索が「1ページずつめくる」方法だとすれば、二分探索は「毎回真ん中を開いて、半分を切り捨てる」方法だ。1000ページの辞書でも、10回開けば見つかる。その理由がO(log n)だ。
この記事でわかること
- 二分探索の動作を辞書の比喩でステップごとに理解する
- O(log n)が「なぜそれだけ速いのか」を数字で把握する
- 線形探索との違いと、二分探索を使うべき場面の判断基準
- Pythonでの実装コード(再帰・反復の2パターン)と落とし穴
真ん中を開いて半分に絞る:動作をステップで追う
📌 要点:ソート済み配列の中央要素と目標値を比較し、大小に応じて探索範囲を半分に絞る。これを繰り返すことで1回の比較ごとに候補が半分になり、少ない手数で目標に辿り着く。
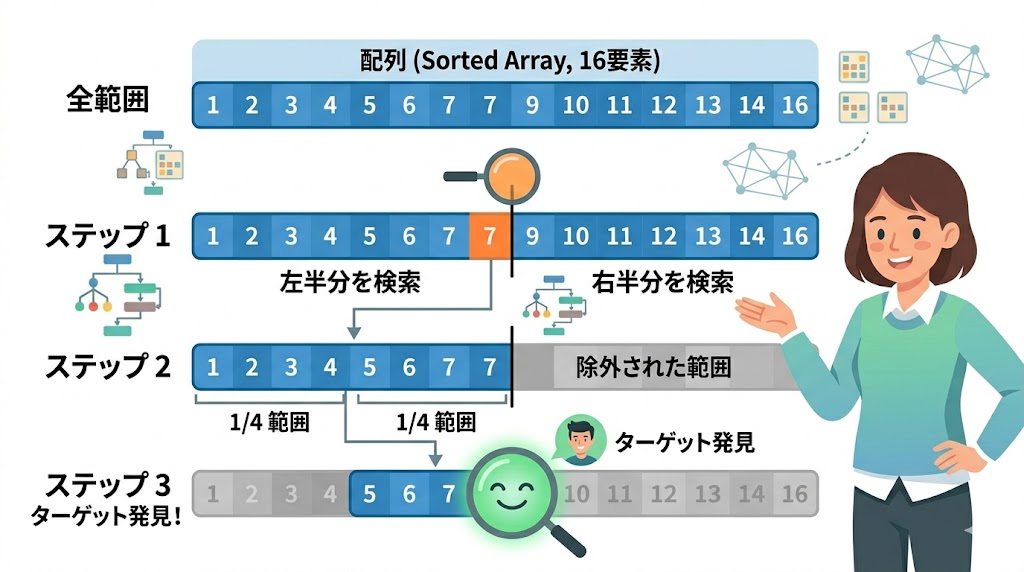
ソート済みの16要素の配列から「13」を探してみよう。辞書で言えば50音順に並んだ16単語から特定の1語を探す場面だ。
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31]
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15ステップ1:真ん中を開く
左端 = 0、右端 = 15
中央 = (0 + 15) // 2 = 7 → 値は 15
15 > 13 なので → 左半分に絞る(右端を6に変更)ステップ2:残り左半分の真ん中を開く
左端 = 0、右端 = 6
中央 = (0 + 6) // 2 = 3 → 値は 7
7 < 13 なので → 右半分に絞る(左端を4に変更)ステップ3:さらに絞る
左端 = 4、右端 = 6
中央 = (4 + 6) // 2 = 5 → 値は 11
11 < 13 なので → 右半分に絞る(左端を6に変更)ステップ4:最後の1つ
左端 = 6、右端 = 6
中央 = 6 → 値は 13
13 == 13 → 見つかった!16要素からたったの4回で見つかった。線形探索なら最悪16回かかるところを。
| ステップ | 探索範囲 | 中央の値 | 判断 |
|---|---|---|---|
| 1 | 16要素 | 15 | 左へ(右半分を切り捨て) |
| 2 | 8要素 | 7 | 右へ(左半分を切り捨て) |
| 3 | 4要素 | 11 | 右へ(左半分を切り捨て) |
| 4 | 2要素 | 13 | 発見 |
辞書を開くたびに、調べるべきページが半分になっていく。この「毎回半分に切る」という操作が二分探索の本質だ。
二分探索の絶対条件:配列がソートされていること
ここで重要なことを言う。二分探索は「ソートされていないデータには使えない」。
辞書を考えると当たり前だ。50音順に並んでいない辞書で「真ん中を開いて前後に分ける」はまったく意味をなさない。前半に何が書いてあるかも予測できない。
二分探索は「ソート済み配列」という前提があって初めて動く。この条件を忘れると、間違った結果を返すバグが生まれる。
O(log n)とは何か:辞書が2倍になっても1回しか増えない
📌 要点:O(log n)は探索範囲を毎回半分にする操作の回数。データが2倍になっても必要な手数は1回しか増えない。100万件でも最大20回で見つかるという驚異的な効率を持つ。
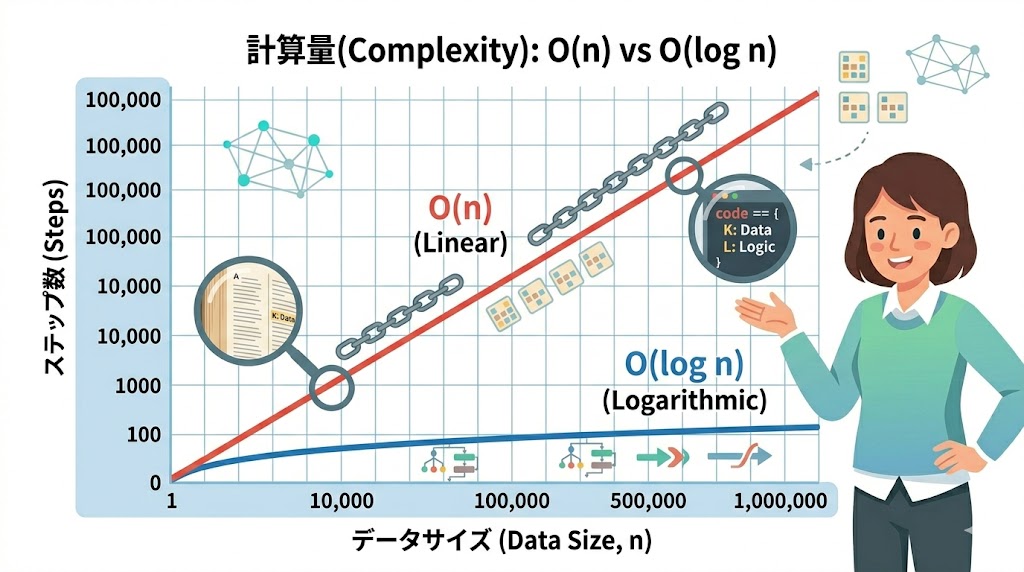
二分探索の計算量は O(log n) だ。logの底は2。つまり「2で何回割り切れるか」だ。
| データ件数 | 二分探索の最大手数 | 線形探索の最大手数 |
|---|---|---|
| 16件 | 4回 | 16回 |
| 256件 | 8回 | 256回 |
| 1,000件 | 10回 | 1,000回 |
| 100万件 | 20回 | 100万回 |
| 10億件 | 30回 | 10億回 |
10億件のデータでも、最大30回で見つかる。
もう少し感覚をつかむために比較してみよう。
「1000ページの辞書を1ページずつめくる」 → 最悪1000回のページめくり。
「1000ページの辞書を真ん中から開いて絞る」 → 最悪10回で目的のページに到達。
データが2倍の2000ページになっても、必要な手数は11回に増えるだけだ。「データが2倍になっても手数は1回しか増えない」——これがO(log n)の直感だ。
Pythonで実装する:反復版と再帰版
📌 要点:二分探索の実装は「反復(ループ)版」と「再帰版」の2パターンある。実用では反復版が安全。再帰版はコードが直感的だが、深い再帰でスタックオーバーフローが起きうる。
反復版(推奨)
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2 # 真ん中のページを開く
if arr[mid] == target:
return mid # 見つかった
elif arr[mid] < target:
left = mid + 1 # 右半分に絞る
else:
right = mid - 1 # 左半分に絞る
return -1 # 見つからなかった
# 実行例
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
print(binary_search(arr, 13)) # → 6(インデックス6に13がある)
print(binary_search(arr, 4)) # → -1(存在しない)再帰版(構造を理解したい場合)
def binary_search_recursive(arr, target, left, right):
if left > right:
return -1 # 探索範囲がなくなった → 存在しない
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
return binary_search_recursive(arr, target, mid + 1, right)
else:
return binary_search_recursive(arr, target, left, mid - 1)
# 実行例
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
print(binary_search_recursive(arr, 13, 0, len(arr) - 1)) # → 6再帰版は「辞書を半分に切る」動作がコードにそのまま現れていて読みやすい。ただし、100万件のデータに対して再帰を使うとPythonのデフォルト再帰上限(1000回)に引っかかる可能性がある。実用では反復版が安全だ。
Pythonの標準ライブラリ bisect を使う
import bisect
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
# 挿入位置を返す(13があるインデックス)
idx = bisect.bisect_left(arr, 13)
print(idx) # → 6
print(arr[idx] == 13) # → True(存在確認)本番コードで二分探索を使うなら bisect が最も安全で高速だ。自前実装のバグリスクがゼロになる。
線形探索との使い分け:どちらを選ぶか
📌 要点:ソート済みで大量データなら二分探索、ソートが保証されないか少量データなら線形探索が合理的。ソートのコストも考慮すると、一度しか検索しないなら線形探索のほうが速いことがある。
情シス部門で資産管理システムの検索ロジックを見直したとき、こういう状況があった。数千件の機器データを毎日何百回も検索する処理なのに、毎回リストを先頭から走査していた。データがすでに管理番号順でソート済みだったので二分探索に変えたところ、バッチ処理の時間が大幅に短縮された。「ソートされていることに気づいていなかった」だけで、ずっと非効率な方法を使い続けていたわけだ。
| 状況 | 推奨 | 理由 |
|---|---|---|
| ソート済み・大量データ・繰り返し検索 | 二分探索 | O(log n)の恩恵が最大に出る |
| ソートなし・小量データ | 線形探索 | ソートのコスト(O(n log n))が見合わない |
| 一度しか検索しない | 線形探索 | ソートの前処理コストを回収できない |
| データが頻繁に更新される | ハッシュテーブル | 更新のたびにソートが必要になる |
| 範囲検索(○以上○以下) | 二分探索 | 境界を効率的に特定できる |
「ソートコストを払えるか」「何回検索するか」——この2軸で判断するといい。
二分探索の応用:「境界を探す」使い方
📌 要点:二分探索は「特定の値を探す」だけでなく、「条件を満たす最初の位置を探す」用途でも使われる。単調な条件(ある値以上の最初の要素など)がある問題なら二分探索が適用できる。
二分探索を「特定の値を探す」だけに使うのはもったいない。「条件を満たす最初・最後の位置を探す」という応用が実務でよく出てくる。
import bisect
# 「13以上の最初の要素のインデックス」を探す
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
idx = bisect.bisect_left(arr, 13)
print(idx) # → 6(インデックス6から13以上が始まる)
print(arr[idx:]) # → [13, 15, 17, 19](13以上の全要素)
# 「13より大きい最初の要素のインデックス」を探す
idx2 = bisect.bisect_right(arr, 13)
print(arr[idx2:]) # → [15, 17, 19](13より大きい全要素)「単価1000円以上の商品を全件取得」「スコア80点以上の社員リストを取得」——こういった範囲検索も、ソート済みデータ×二分探索で効率的に処理できる。
FAQ
- Q二分探索と二分探索木(BST)は同じですか?
- A
同じではありません。
二分探索はソート済み配列に対する「探索アルゴリズム」です。二分探索木(Binary Search Tree)は、二分探索と同じ大小比較のルールで構造化された「データ構造」です。二分探索木に対して探索を行う際は二分探索と同様の比較ロジックを使いますが、対象が配列かツリー構造かが異なります。
- Q二分探索はソートされていない配列に使えますか?
- A
ソートされていない配列には使えません。
ソートされていない配列に二分探索を適用すると、「左半分・右半分」の判断が意味をなさず、正しい結果を返しません。二分探索を使う前にsorted()でソートするか、最初からソート済みのデータ構造を選ぶ必要があります。
- Q中央インデックスを
(left + right) // 2で計算する際に整数オーバーフローは起きませんか? - A
Pythonでは整数に上限がないためオーバーフローは起きません。ただしCやJavaでは
left + rightがint型の上限を超える場合があり、left + (right - left) // 2と書くのが安全です。言語を変えるときに注意してください。
- QPythonのbisectモジュールはいつ使うべきですか?
- A
本番コードで二分探索が必要な場合は、ほぼ常に
bisectを使うべきです。
自前実装に比べてバグリスクがゼロで、C実装のため高速です。面接やアルゴリズム学習での自前実装と、業務コードでのbisect使用を使い分けてください。
- Qデータが重複している配列に二分探索を使うとどうなりますか?
- A
基本実装では重複する値の「どれか1つ」を返します。最初の一致・最後の一致を確実に取得したい場合は
bisect_left(最初)またはbisect_right(最後の次)を使うことで正確に制御できます。
- Q二分探索の空間計算量はどれくらいですか?
- A
空間計算量の反復版はO(1)です。
追加のメモリをほぼ使わず、変数3つ(left・right・mid)のみで動きます。再帰版はO(log n)です。再帰の深さ分だけコールスタックが積まれます。メモリ効率の観点でも反復版が推奨されます。
まとめ
- 二分探索は辞書を真ん中から開いて前後を判断しながら絞り込む探し方そのもの
- 計算量はO(log n)。データが2倍になっても手数は1回しか増えない
- ソート済み配列が絶対条件。ソートされていないデータには使えない
- 線形探索と使い分ける基準は「ソートされているか」「何回検索するか」の2軸
- 実用ではPythonの
bisectモジュールを使うのが安全で最速
1000ページの辞書を1ページずつめくる人はいない。真ん中を開いて、「前か後か」を判断して半分を捨てる。その動作を毎回繰り返すだけで、どんなに厚い辞書でも10数回で目的のページに辿り着ける。「毎回半分に捨てる」という単純なルールが、驚異的な効率を生む。 これが二分探索の本質だ。
関連記事
線形探索との比較で二分探索の強みをさらに理解したい方はこちら。
→ 線形探索とは?回転寿司で理解するO(n)の仕組み
アルゴリズムの計算量を体系的に理解したい方はこちら。
→ アルゴリズムのオーダー記法をマンガで理解する
“`

