

128GBのMacBook Proがあれば、ローカルLLMは実用域に達するのか。
答えから言う。達する。ただし「誰にでも必要か」と聞かれたら、答えは別だ。
IT部門で長年システム投資の費用対効果を評価してきた視点から、この選択が「誰にとって合理的か」を正直に整理する。
この記事でわかること
- 128GBメモリがローカルLLMで「分水嶺」になる理由がわかる
- ローカルLLMがもたらす3つの自由の実態がわかる
- 3年間の実質コストと、投資が合う人・合わない人が判断できる
なぜ128GBが分水嶺なのか
📌 要点:LLMのメモリ要求は70Bクラスのモデルで約50〜80GBが必要。128GBがあって初めて「実用・創作レベル」のモデルが量子化版で動く。それ以下では能力が大きく制限される。
ローカルLLMでは「どのサイズのモデルを動かせるか」がすべてだ。Appleシリコンのユニファイドメモリは、CPUとGPUが共有するため、LLMのメモリ要求を効率的に満たせる。
| メモリ | 実用モデル規模 | 能力レベル |
|---|---|---|
| 32GB | 7B〜13B | 趣味・短文生成レベル |
| 64GB | 13B〜34B | 実験・検証レベル |
| 128GB | 70B級(量子化) | 実務・創作・相棒レベル |
70Bクラス(700億パラメータ)に到達して初めて、長文の安定性・推論の一貫性・キャラクター維持がクラウド最上位層に肉薄する。「AIっぽい出力」が「使える相棒」へと変わる境界線が128GBだ。
動作速度は秒間8〜12トークン程度(M4 Max、70B量子化時)。人間が読む速度と同等かやや速いくらいで、ストレスなく使える。
ローカルLLMがもたらす3つの自由
📌 要点:①検閲・ポリシー変更からの解放、②API課金の心理的ブレーキ消滅、③機密情報の完全ローカル処理。この3点が主な動機になる。
① 検閲とポリシー変更からの解放
クラウドAIはある日突然、ポリシー更新でこれまで使えていた機能が制限されることがある。ローカルLLMはモデルを自分で選び、自分で責任を持つ。特定のテーマがブロックされることも、回答を拒絶されることもない。
② API課金と心理的ブレーキの消滅
従量課金は「これを聞いていいのか」という心理的ブレーキを生む。ローカルは電気代以外完全無料だ。「試しに1,000個のプロンプトを流してみる」という実験が気兼ねなくできる。
③ 機密情報の完全ローカル処理
未公開の企画書、クライアントの情報、個人の思考。これらを1ビットも外部送信せずMac内部で完結できる。情シス部門では機密情報の外部送信リスクが常に議論になるが、ローカルLLMはその問題を物理的に解決する。
実質コストとリセール戦略
📌 要点:初期投資約813,000円も、3年後の売却(約280,000円)を含めた実質負担は約530,000円。月額換算約15,000円。API課金が月2万円超のヘビーユーザーには合理的な選択になる。
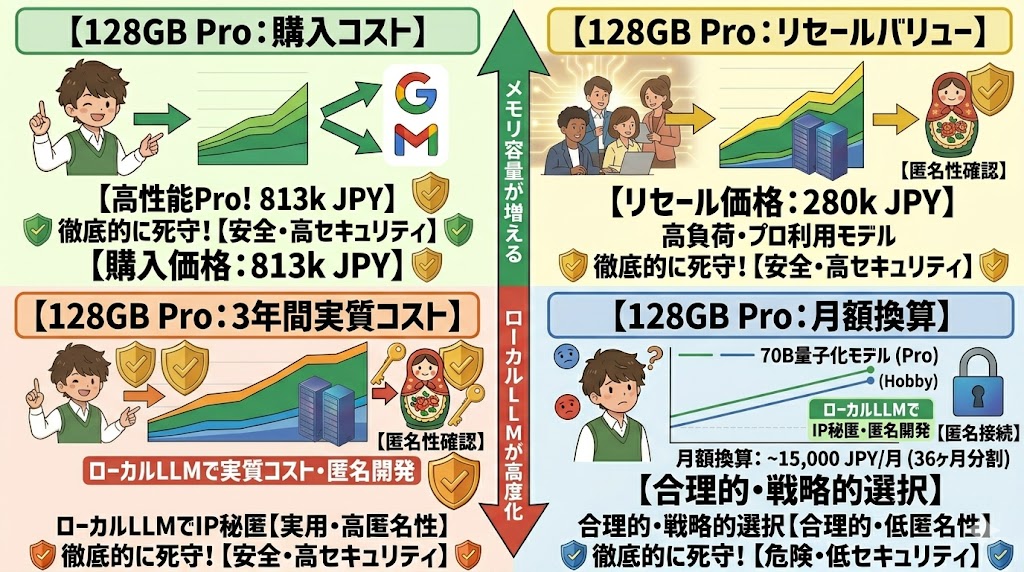
高く見える価格も、分解して考えると別の姿が見えてくる。
| 項目 | 金額 |
|---|---|
| 初期投資(M4 Max 128GB構成) | 約813,000円 |
| 3年後売却予想価格 | ▲約280,000円 |
| 実質負担(3年間) | 約533,000円 |
| 月額換算 | 約15,000円 |
Appleシリコンは中古市場でのリセール価値が高い。3年後でも50〜60%前後の価格で売れることが多い(実際の相場は時期により変動するため要確認)。
この月額15,000円が「高い」か「安い」かは、使い方次第だ。
- 合う人:Claude Pro + ChatGPT Plus + API従量課金で月3〜5万円払っているヘビーユーザー
- 合わない人:月数千円のライトユーザー。クラウドAPIで十分対応できる
デメリットも直視する
📌 要点:セットアップの技術的ハードル・生成速度の制限・発熱と騒音は正直に評価すべきデメリット。「技術的なプロセスを楽しめるか」が向き不向きの分岐点。
正直に言う。万人向けではない。
- セットアップは自己責任:Ollama等のツール理解・量子化の概念・モデル選定。このプロセスを楽しめない人に自由は使いこなせない
- 生成速度の物理的限界:70Bで秒間8〜12トークン。クラウドの最速モデルには劣る場面がある
- 発熱と騒音:フル稼働時のファン音は気になる。カフェでの使用には注意が必要
「ローカルLLMを使いたい」ではなく「ローカルLLMを設定して動かすプロセス自体が楽しい」と思える人でなければ、コスト対効果は薄れる。
FAQ
- Qどんなモデルを最初に試せばいいか?
- A
Llama 3.1 70B(量子化版)が2026年時点での実用入門点として最もバランスが良い。
Ollama(https://ollama.ai)を使えばコマンド1行でダウンロード・実行できる。他にQwen2.5・Mistral系も人気が高い。
- Q128GBと64GBで体感差はあるか?
- A
2倍の差はかなり大きい。
64GB(34B量子化)と128GB(70B量子化)では、長文の文脈維持・複雑な推論・キャラクターの一貫性で体感できる差がある。「実務で使えるか」の境界線が128GBと64GBの間にある。
- QOllamaなどのローカルLLMツールは難しいか?
- A
Ollamaはターミナルから
ollama run llama3.1と打つだけで使い始められる。
モデルをGUI操作できるOpen WebUIなどのフロントエンドを組み合わせると、ChatGPTに近いインターフェースで使える。
- QローカルLLMとクラウドLLMを使い分けるべきか?
- A
ローカルLLMとクラウドLLMを用途で分けるのが現実的だ。
機密情報・実験的な使い方・コスト節約はローカル。最新情報の検索・マルチモーダル処理・最高精度が必要なタスクはクラウド。両方維持するのが2026年現在の最適解だと思っている。
- Q法人利用での注意点は何か?
- A
モデルのライセンスを確認すること。
Llama系は商用利用可能だが、モデルによっては制限がある。また社内情報をローカルLLMに入力すること自体は外部送信がないためリスクが低いが、企業のAI利用ポリシーを事前に確認することを推奨する。
まとめ
- 128GBは70B量子化モデルが動く「実務・相棒レベル」への分水嶺
- ローカルLLMの3大価値:検閲からの自由・API課金ゼロ・機密情報のローカル完結
- 3年間の実質コストは月額約15,000円。APIヘビーユーザーには合理的な投資になる
- セットアップの技術的プロセスを楽しめる人・機密性要件の高い人に向いている
- クラウドとローカルの使い分けが2026年現在の最適解。どちらか一方では補えない用途がある
🔗 あわせて読みたい:

