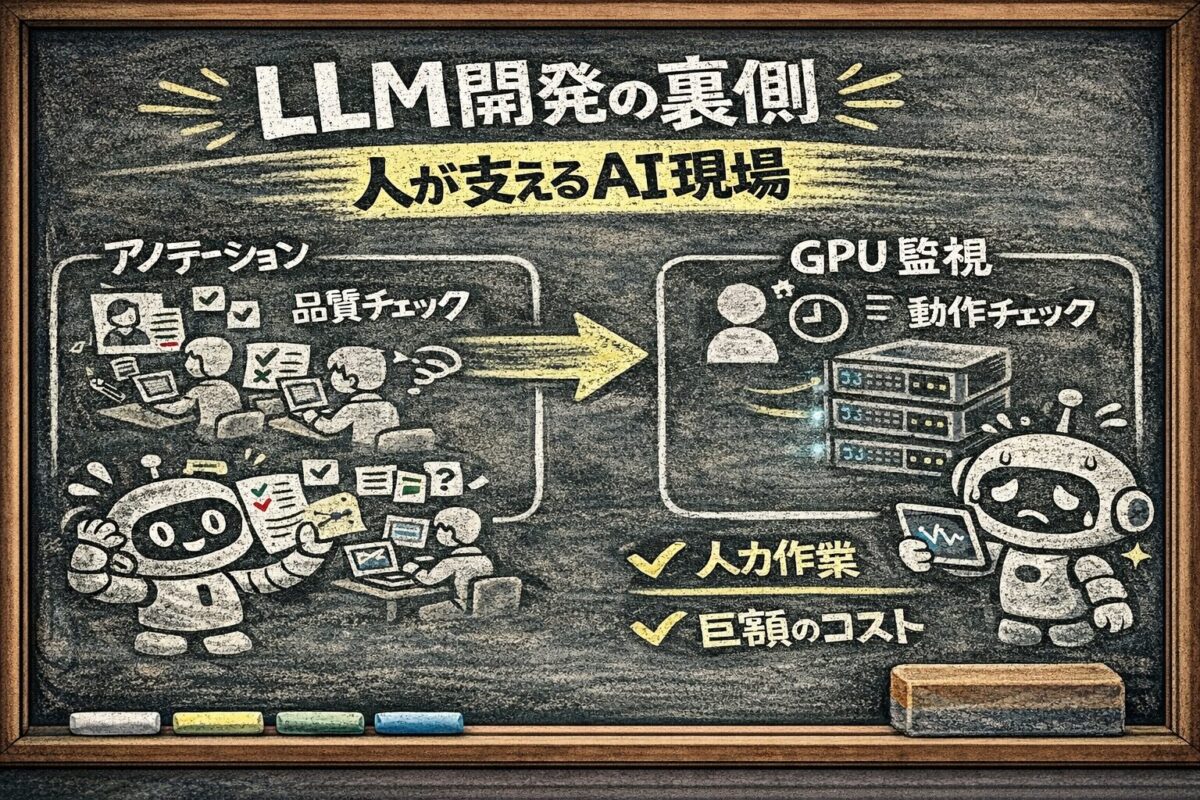
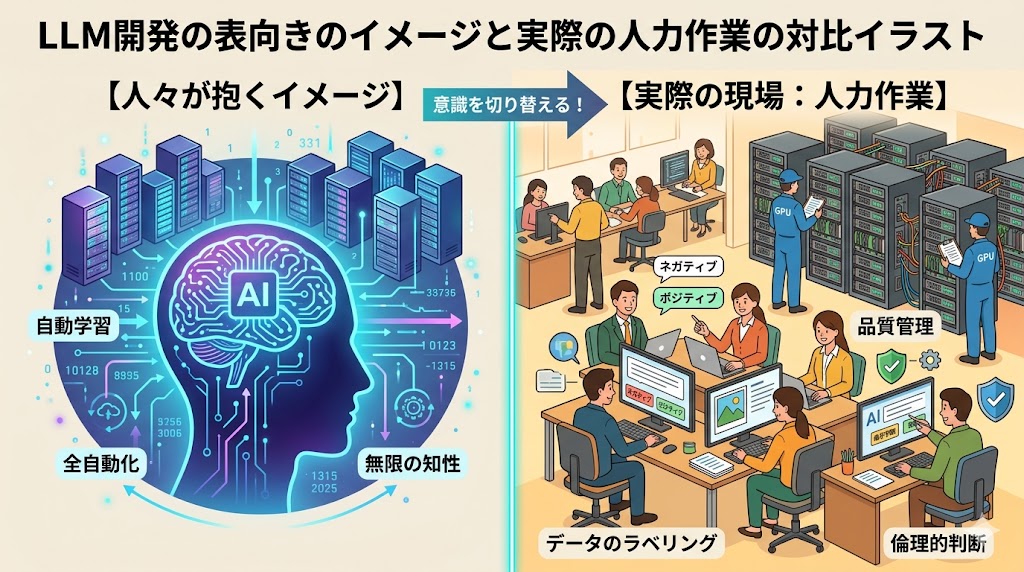
「大規模言語モデルは全部自動で学習している」
そう思っているなら、その認識は今日アップデートしてほしい。ChatGPTやClaudeの裏側には、想像以上に多くの「人間の手作業」が入っている。
IT部門でシステム調達・ベンダー評価をしてきた経験から、AI開発のコスト構造を正確に理解することは、AIツール選定にも直結する知識だと感じている。
この記事でわかること
- LLM開発がなぜ「人力作業」に大きく依存しているのかがわかる
- アノテーション・RLHF・GPU監視の役割がわかる
- AIが進化するほど人間の役割が変化する(消えない)理由がわかる
なぜLLM開発は人手に依存するのか
📌 要点:モデルは与えられたデータをそのまま「正解」として学習する。「そのデータが正しいか」を判断する最終的なチェックは、人間にしかできない。
LLMは確かに膨大なデータで学習する。でも、一つの根源的な問いにぶつかる。「そのデータが正しいと、誰が保証するのか?」
モデルは入力されたデータを全部「正解」として飲み込む。間違ったデータも、偏ったデータも、悪意のあるデータも例外なく。だから以下の工程が必須になる。
- データクリーニング:ノイズ・重複・差別的表現の削除
- アノテーション:「この回答は適切か」「どちらが良い回答か」のラベル付け
- RLHF(人間のフィードバックによる強化学習):人間の評価をもとにモデルを調整
- 出力監視:ハルシネーション(もっともらしい嘘)の検知・修正
これらを完全自動化できない理由はシンプルだ。言語の「正しさ」が文脈・文化・価値観に依存するため、数式のように定義しにくいからだ。
アノテーションという重労働と「ベビーシッター」の実態
📌 要点:高品質な教師データを作るアノテーション作業は自動化困難で、人的負担が最も高い工程。モデルの継続的な監視・修正担当者は「ベビーシッター」と呼ばれる。
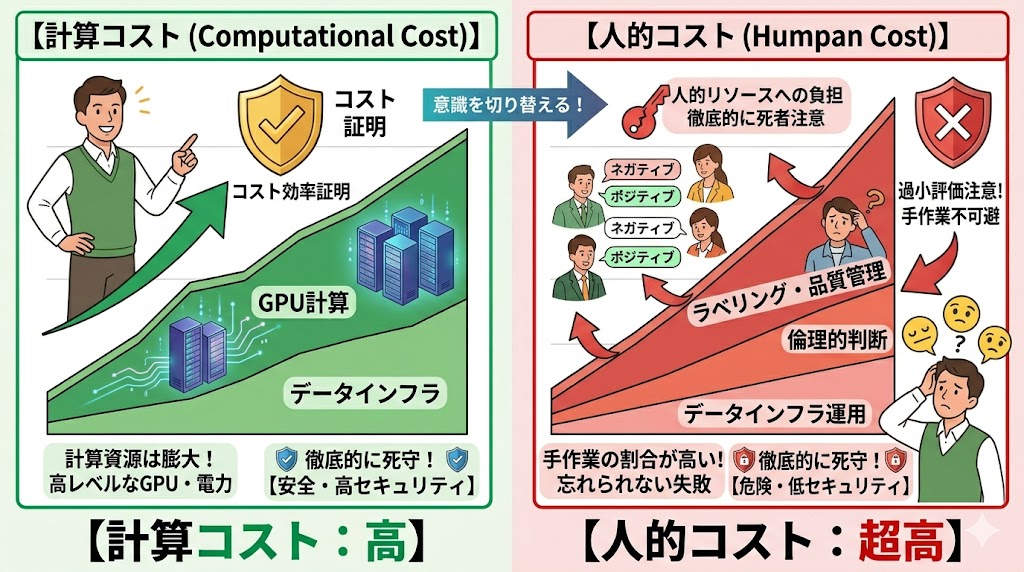
LLM開発のコスト構造を整理すると、意外な事実が見える。
| 工程 | 自動化度 | 人的負担 |
|---|---|---|
| データ収集(Webクローリング等) | 高 | 低 |
| データ精査(有害コンテンツ排除) | 中 | 高 |
| アノテーション(教師データ作成) | 低 | 最高 |
| モデル学習(GPU計算) | 高 | 低 |
| 出力監視(ハルシネーション検知) | 中 | 高 |
「モデル学習(計算コスト)がメインコスト」と思われがちだが、アノテーションと出力監視の人的コストが品質を左右する最大のボトルネックだ。
また、モデルは一度学習すれば終わりではない。常にハルシネーションを監視し、新しい脆弱性に対応し、ユーザーフィードバックをモデルに反映させる必要がある。これを担当するエンジニアが開発現場で「モデルのベビーシッター」と呼ばれる所以だ。
IT部門でも似た感覚がある。システムを「導入して終わり」と思っている人は必ず痛い目に遭う。どんな優れたシステムも、運用・監視・調整を続ける人間の管理なしでは品質を保てない。LLMも同じだ。
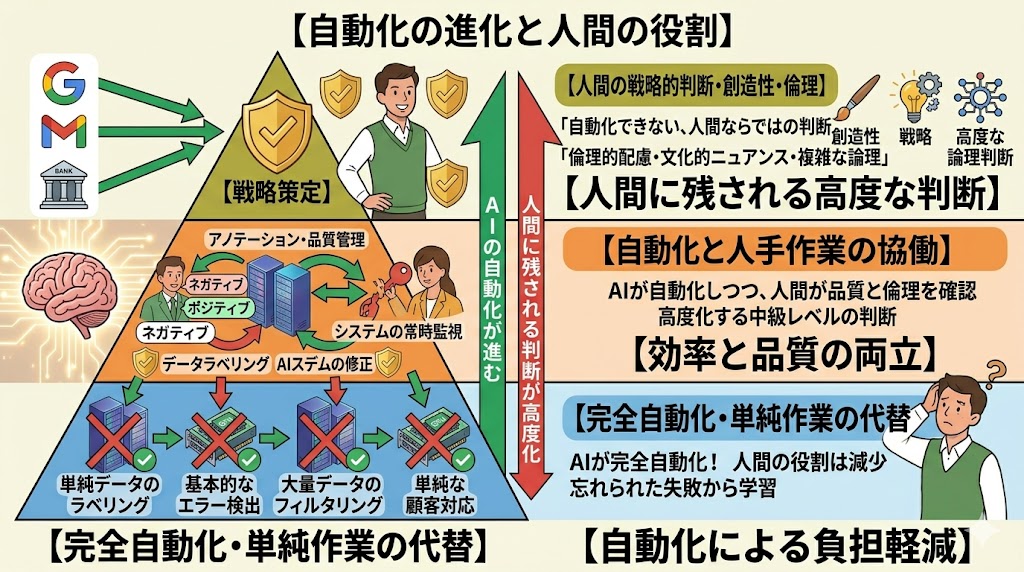
AIが進化するほど人間の役割は高度化する
📌 要点:AIが自動化できる範囲が広がるほど、残される人間の役割は「倫理・文化・高度な論理判断」という複雑なものに移行する。人間の仕事は消えるのではなく質が変わる。
「AIが発展すれば人間の仕事が消える」という議論がある。LLM開発の現場を見ると、少し違う景色が見えてくる。
AIの自動化能力が高まるほど、人間に残される判断は「簡単には自動化できない複雑なもの」になる。
- 倫理判断:この出力は特定の文化・価値観で受け入れられるか
- 文脈理解:この回答は表面的には正しいが、状況に適切か
- 高度な論理チェック:多段階の推論が本当に正しいか
これは消去ではなく昇格だ。繰り返し可能な判断はAIが担い、人間は「繰り返しパターンを作ること自体」に集中できる。
「LLMは人間拡張装置である」この本質を理解した組織は、AIを「人間の仕事を奪うもの」ではなく「人間の判断力を増幅するもの」として使える。
FAQ
- Qアノテーション作業はどのくらいのコストがかかるのか?
- A
コストは規模・品質要求によって大きく異なる。
業界の一般的な話では、高品質なアノテーションにはモデル計算コストと同等かそれ以上の費用がかかることがある。特に多言語対応・専門領域(医療・法律)のアノテーションは単価が高い。
- QRLHFとはどういう仕組みか?
- A
Reinforcement Learning from Human Feedback(人間のフィードバックによる強化学習)の略。
同じ質問に対する複数の回答を人間が評価し、その評価データをもとに「人間が好む回答を出すよう」モデルを調整する手法。ChatGPTの開発で広く知られるようになった。
- Qハルシネーションはなぜ起きるのか?
- A
LLMは「統計的に次に来やすい単語」を予測して文章を生成するため、真実かどうかではなく「それらしい文章かどうか」で出力を決める。
正確な事実データベースを持っているわけではないため、存在しない論文や人名を自信満々に生成することがある。
- QAIツール選定で「アノテーション品質」はどう評価すればいいのか?
- A
外部からの直接評価は難しいが、「評価ベンチマークの種類と数」「安全性に関する透明性レポートの公開有無」「ユーザーフィードバックの反映速度」が間接的な指標になる。
- Q自社でLLMを開発・ファインチューニングする場合のアノテーションはどうすれば良いか?
- A
社内専門家によるアノテーションが品質面では最善だが、コストが高い。
専門のアノテーション会社(Scale AI等)への外注も選択肢だが、機密情報の取り扱いに注意が必要。小規模なファインチューニングなら500〜2000件程度の高品質データから始めるのが現実的だ。
まとめ
- LLM開発は「全自動」ではなく、アノテーション・品質管理・監視に大量の人的作業が必要
- アノテーション工程は自動化困難で、人的負担が最も高くモデル品質を左右するボトルネック
- モデルの継続的な監視・修正担当者は「ベビーシッター」と呼ばれ、開発後も重要な役割を持つ
- AIが進化するほど人間の役割は「倫理・文化・高度な論理」という複雑判断に移行(消えるのではなく昇格)
- AIは「人間拡張装置」。この本質を理解した組織がAIを最大限に活かせる
🔗 あわせて読みたい:
